Modules
All Available Functions
- class torch_activation.ABU(activation_pool=None, constrain_weights='none', init_weights=None, bias=False, init_bias=0.0)[source]
Applies the Adaptive Blending Unit (ABU) function:
\(\text{ABU}(z_l) = \sum_{j=0}^{n} a_{j,l} \cdot g_j(z_l) + b\)
where \(g_j(z_l)\) is an activation function from a pool of n activation functions, \(a_{j,l}\) is a trainable weighting parameter for each layer l and activation function g_j, and \(b\) is an optional trainable bias term.
- Parameters:
activation_pool (list, optional) – List of activation functions to blend. Default: [nn.Tanh(), nn.ELU(), nn.ReLU(), nn.SiLU(), nn.Identity()]
constrain_weights (str, optional) – Method to constrain weights. Options: ‘none’, ‘sum_to_one’, ‘abs_sum_to_one’, ‘clip_and_normalize’, ‘softmax’. Default: ‘none’
init_weights (list, optional) – Initial weights for each activation. If None, initialized to 1/n. Default: None
bias (bool, optional) – If True, adds a learnable bias term. Default: False
init_bias (float, optional) – Initial value for the bias term. Default: 0.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ABU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ACONB(a: float = 1.0, b: float = 0.25, learnable: bool = False, inplace: bool = False)[source]
Applies the ACON-B activation function:
\(\text{ACON-B}(x) = (1 - b) \cdot x \cdot \sigma(a \cdot (1 - b) \cdot x) + b \cdot x\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
b (float, optional) – Parameter controlling the linear component. Default: 0.25
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ACONB(a=1.0, b=0.25) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ACONB(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ACONC(a: float = 1.0, b: float = 0.0, c: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the ACON-C activation function:
\(\text{ACON-C}(x) = (c - b) \cdot x \cdot \sigma(a \cdot (c - b) \cdot x) + b \cdot x\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
b (float, optional) – Parameter controlling the linear component. Default: 0.0
c (float, optional) – Parameter controlling the swish component. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ACONC(a=1.0, b=0.0, c=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ACONC(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AGumb(a_init: float = 1.0)[source]
Applies the Adaptive Gumbel function:
\(\text{AGumb}(x) = 1 - (1 + a \cdot \exp(x))^{-1}\)
where \(a\) is a trainable positive parameter.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = AGumb(a_init=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AHAF(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive Hybrid Activation Function:
\(\text{AHAF}(x) = a \cdot x \cdot \sigma(b \cdot x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
b (float, optional) – Parameter controlling the shape of the function. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AHAF(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AHAF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ALiSA(init_ar: float = 1.0, init_al: float = 0.1)[source]
Applies the Adaptive Linearized Sigmoidal Activation (ALiSA) function:
\(\text{ALiSA}(z_i) = \begin{cases} a^r_i z_i - a^r_i + 1, & z_i \geq 1 \\ z_i, & 1 > z_i > 0 \\ a^l_i z_i, & z_i \leq 0 \end{cases}\)
where \(a^r_i\) and \(a^l_i\) are trainable parameters.
- Parameters:
init_ar (float, optional) – Initial value for the right slope parameter ar. Default: 1.0
init_al (float, optional) – Initial value for the left slope parameter al. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ALiSA(init_ar=1.0, init_al=0.1) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AOAF(a: float = 0.1, b: float = 0.17, c: float = 0.17, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive Offset Activation Function:
\(\text{AOAF}(x) = \max(0, x - b \cdot a) + c \cdot a\)
- Parameters:
a (float, optional) – Adaptive parameter. Default: 0.1
b (float, optional) – Offset scaling parameter. Default: 0.17
c (float, optional) – Bias scaling parameter. Default: 0.17
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AOAF(a=0.1, b=0.17, c=0.17) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AOAF(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.APAF(activation_pool=None, init_weights=1.0)[source]
Applies the Average of a Pool of Activation Functions (APAF):
\(\text{APAF}(z_i) = \frac{\sum_{j=0}^{n} a_{j,i} h_j(z_i)}{\sum_{j=0}^{n} a_{j,i}}\)
where \(h_j\) are activation functions from a pool and \(a_{j,i}\) are trainable parameters.
- Parameters:
activation_pool (list, optional) – List of activation functions to average. Default: [nn.ReLU(), nn.Sigmoid(), nn.Tanh(), nn.Identity()]
init_weights (float, optional) – Initial value for the weights. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = APAF() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AQuLU(a: float = 0.2, b: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive Quadratic Linear Unit function:
- :math:`text{AQuLU}(x) = begin{cases}
x, & x geq frac{1 - b}{a} \ a cdot x^2 + b cdot x, & -frac{b}{a} leq x < frac{1 - b}{a} \ 0, & x < -frac{b}{a}
end{cases}`
- Parameters:
a (float, optional) – Parameter controlling the quadratic component. Default: 0.2
b (float, optional) – Parameter controlling the linear component. Default: 0.1
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AQuLU(a=0.2, b=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AQuLU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AReLU(a: float = 0.9, b: float = 2.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Attention-based ReLU function:
\(\text{AReLU}(x) = \begin{cases} (1 + \sigma(b)) \cdot x, & x \geq 0 \\ C(a) \cdot x, & x < 0 \end{cases}\)
where \(\sigma\) is the sigmoid function and \(C(a)\) is a function of parameter \(a\).
- Parameters:
a (float, optional) – Parameter for negative slope. Default: 0.9
b (float, optional) – Parameter for positive slope. Default: 2.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AReLU(a=0.9, b=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ASSF(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive Slope Sigmoidal Function:
\(\text{ASSF}(x) = \sigma(a \cdot x) = \frac{1}{1 + \exp(-a \cdot x)}\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Slope parameter. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ASSF(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ASSF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AbsLU(a: float = 0.5, inplace: bool = False)[source]
Applies the Absolute Linear Unit activation function:
\[\begin{split}\text{AbsLU}(z) = \begin{cases} z, & z \geq 0, \\ a|z|, & z < 0, \end{cases}\end{split}\]where \(a \in [0, 1]\).
- Parameters:
a (float, optional) – Scaling parameter for negative inputs. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
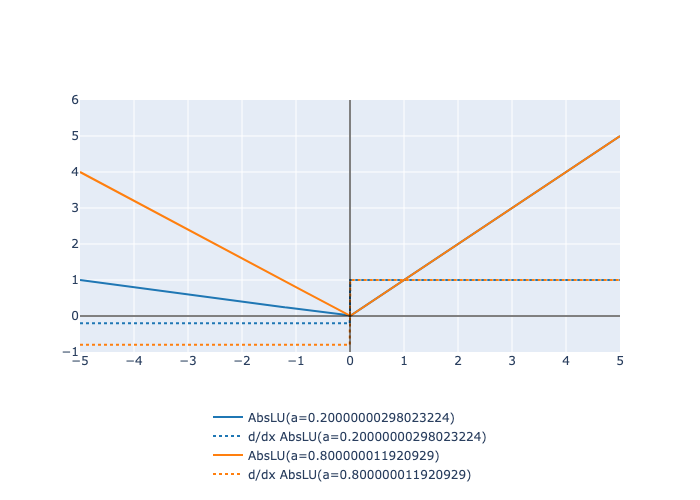
Examples:
>>> m = torch_activation.AbsLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AbsLU(a=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AdaptiveCombination1(a: float = 0.5, lrelu_slope: float = 0.01, elu_alpha: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
- Note:
This is a temporary naming.
Applies an adaptive combination of activation functions:
\(\text{AdaptiveCombination1}(x) = a \cdot \text{LReLU}(x) + (1 - a) \cdot \text{ELU}(x)\)
- Parameters:
a (float, optional) – Mixing parameter. Default: 0.5
lrelu_slope (float, optional) – Negative slope for LReLU. Default: 0.01
elu_alpha (float, optional) – Alpha parameter for ELU. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AdaptiveCombination1(a=0.7) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AdaptiveCombination1(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AdaptiveCombination2(a: float = 1.0, prelu_slope: float = 0.01, pelu_alpha: float = 1.0, pelu_beta: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
- Note:
This is a temporary naming.
Applies an adaptive combination of activation functions with sigmoid gating:
\(\text{AdaptiveCombination2}(x) = \sigma(a \cdot x) \cdot \text{PReLU}(x) + (1 - \sigma(a \cdot x)) \cdot \text{PELU}(x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Gating parameter. Default: 1.0
prelu_slope (float, optional) – Negative slope for PReLU. Default: 0.01
pelu_alpha (float, optional) – Alpha parameter for PELU. Default: 1.0
pelu_beta (float, optional) – Beta parameter for PELU. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AdaptiveCombination2(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AdaptiveCombination2(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AdaptiveHardTanh(a: float = 1.0, b: float = 0.0, min_val: float = -1.0, max_val: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive HardTanh function:
\(\text{AdaptiveHardTanh}(x) = \text{HardTanh}(a_t \cdot (x - b))\)
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
b (float, optional) – Shift parameter. Default: 0.0
min_val (float, optional) – Minimum value of the HardTanh. Default: -1.0
max_val (float, optional) – Maximum value of the HardTanh. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AdaptiveHardTanh(a=2.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AdaptiveHardTanh(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AdaptiveSigmoid(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Adaptive Sigmoid function:
\(\text{AdaptiveSigmoid}(x) = \frac{2}{1 - \exp(-ax)} - \frac{2}{a(1 + \exp(-ax))}\)
where \(a \in (0, \infty)\) is a learnable parameter.
- Parameters:
a (float, optional) – Slope parameter. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.AdaptiveSigmoid(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AdaptiveSigmoid(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.AdaptiveSlopeTanh(a_init: float = 1.0)[source]
Applies the Adaptive Slope Hyperbolic Tangent function:
\(\text{AdaptiveSlopeTanh}(x) = \tanh(a \cdot x)\)
where \(a\) is a trainable parameter.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = AdaptiveSlopeTanh(a_init=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Arctan[source]
Applies the Arctan activation function:
\(\text{Arctan}(z) = \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Arctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ArctanGR[source]
Applies the ArctanGR activation function:
\(\text{ArctanGR}(z) = \frac{\arctan(z)}{1 + \sqrt{2}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ArctanGR() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ArctanSiLU[source]
Applies the Arctan SiLU activation function:
\(\text{ArctanSiLU}(z) = \arctan(z) \cdot \frac{1}{1 + \exp(-z)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ArctanSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.BLReLU(a: float = 0.1, b: float = 1.0, inplace: bool = False)[source]
Applies the Bounded Leaky ReLU activation function:
\[\begin{split}\text{BLReLU}(z) = \begin{cases} az, & z \leq 0, \\ z, & 0 < z < b, \\ az + c, & z \geq b, \end{cases}\end{split}\]where \(c = (1 - a)b\).
- Parameters:
a (float, optional) – Slope parameter for negative and large positive inputs. Default:
0.1b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.BLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BLReLU(a=0.2, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.BLU(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Bendable Linear Unit function:
\(\text{BLU}(x) = a \cdot \sqrt{x^2 + 1} - 1 + x\)
where \(a \in [-1, 1]\) controls the bendability.
- Parameters:
a (float, optional) – Bendability parameter. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.BLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.BReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Bounded ReLU activation function:
\[\begin{split}\text{BReLU}(z) = \min(\max(0, z), a) = \begin{cases} 0, & z \leq 0, \\ z, & 0 < z < a, \\ a, & z \geq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Upper bound for the function’s output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
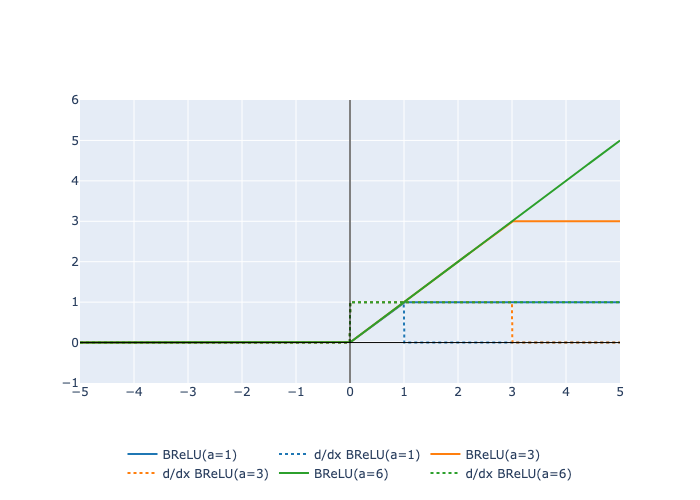
Examples:
>>> m = torch_activation.BReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BReLU(a=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Binary(inplace: bool = False)[source]
Applies the Binary activation function:
\(\text{Binary}(z) = \begin{cases} 0, & z < 0 \\ 1, & z \geq 0 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CCAF(a: float = 0.5, b: float = 0.5, iterations: int = 1)[source]
Applies the Cascade Chaotic Activation Function:
\[f(z_{i+1}) = a \cdot \sin(\pi \cdot b \cdot \sin(\pi z_i))\]where \(a, b \in [0, 1]\).
- Parameters:
a (float, optional) – Amplitude parameter. Default:
0.5b (float, optional) – Inner sine scaling parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.CCAF() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.CCAF(a=0.8, b=0.7, iterations=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CELU(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Continuously Differentiable ELU function:
- :math:`text{CELU}(x) = begin{cases}
x, & x geq 0 \ a cdot left(expleft(frac{x}{a}right) - 1right), & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.CELU(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.CELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CReLU(dim: int = 0)[source]
Applies the Concatenated Rectified Linear Unit activation function.
\(\text{CReLU}(x) = \text{ReLU}(x) \oplus \text{ReLU}(-x)\)
- Parameters:
dim (int, optional) – Dimension along which to concatenate in the output tensor. Default: 1
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
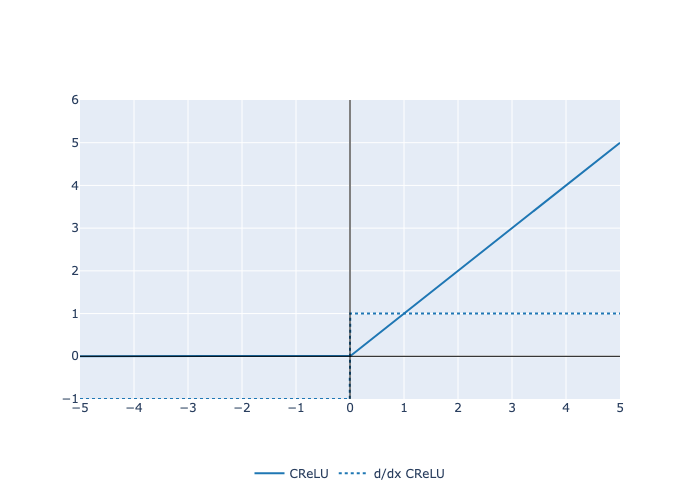
Examples:
>>> m = torch_activation.CReLU() >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = torch_activation.CReLU(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CauchyLinearUnit[source]
Applies the Cauchy Linear Unit activation function:
\(\text{CaLU}(z) = z \cdot \Phi_{\text{Cauchy}}(z) = z \cdot \left( \frac{\arctan(z)}{\pi} + \frac{1}{2} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CauchyLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ChPAF(k=3, init_a=0.1)[source]
Applies the Chebyshev Polynomial-based Activation Function (ChPAF):
\(\text{ChPAF}(z) = \sum_{j=0}^{k} a_j C_j(z)\)
where \(a_j\) are learnable parameters, \(k\) is a fixed hyperparameter denoting the maximum order of used Chebyshev polynomials, and \(C_j(z)\) is a Chebyshev polynomial of order j.
- Parameters:
k (int, optional) – Maximum order of Chebyshev polynomials. Default: 3
init_a (float, optional) – Initial value for the coefficients. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ChPAF(k=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CoLU(inplace=False)[source]
Applies the Collapsing Linear Unit activation function:
\(\text{CoLU}(x) = \frac{x}{1-x \cdot e^{-(x + e^x)}}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
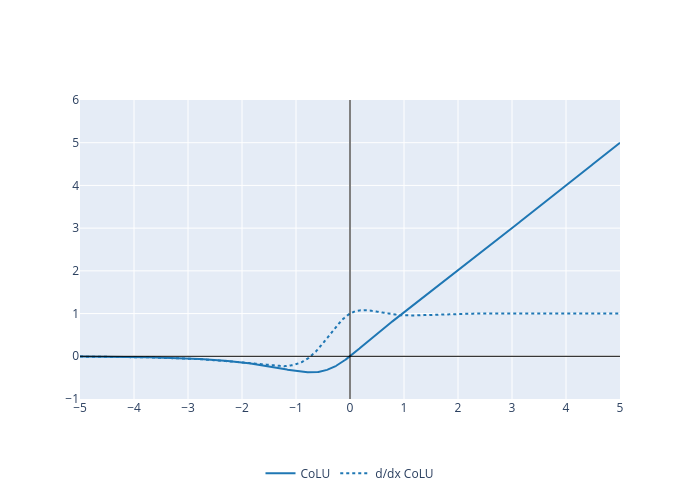
Examples:
>>> m = nn.CoLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.CoLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CollapsingLinearUnit(inplace=False)[source]
Applies the Collapsing Linear Unit activation function:
\(\text{CoLU}(z) = z \cdot \frac{1}{1 - z \exp(-(z + \exp(z)))}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CollapsingLinearUnit() >>> x = torch.randn(2) >>> output = m(x) >>> m = CollapsingLinearUnit(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ComplementaryLogLog[source]
Applies the Complementary LogLog activation function:
\(\text{ComplementaryLogLog}(z) = 1 - \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.CosLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Cosine Linear Unit function:
\(\text{CosLU}(x) = (x + a \cdot \cos(b \cdot x)) \cdot \sigma(x)\)
- Parameters:
a (float, optional) – Scaling factor for the cosine term. Default is 1.0.
b (float, optional) – Frequency factor for the cosine term. Default is 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = CosLU(alpha=2.0, beta=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = CosLU(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DELU(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the DELU activation function:
- :math:`text{DELU}(x) = begin{cases}
(a + 0.5) cdot x + |\exp(-x) - 1|, & x geq 0 \ x cdot sigma(x), & x < 0
end{cases}`
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Scaling parameter. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DELU(a=0.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DKNN(activation_pool=None, init_a=1.0, init_b=1.0)[source]
Applies the Deep Kronecker Neural Network (DKNN) activation function:
\(\text{DKNN}(z_l) = \sum_{j=0}^{n} a_{l,j} g_j(b_{l,j} z_l)\)
where \(g_j\) are fixed activation functions, and \(a_{l,j}\) and \(b_{l,j}\) are trainable parameters.
- Parameters:
activation_pool (list, optional) – List of activation functions to use. Default: [nn.Tanh(), nn.ReLU(), nn.SiLU(), nn.Identity()]
init_a (float, optional) – Initial value for the vertical scaling parameters a. Default: 1.0
init_b (float, optional) – Initial value for the horizontal scaling parameters b. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DKNN() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DLReLU(a: float = 0.01, mse: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Dynamic Leaky ReLU function:
\(\text{DLReLU}(x) = \begin{cases} x, & x \geq 0 \\ a \cdot b_t \cdot x, & x < 0 \end{cases}\)
where \(b_t = \text{MSE}_{t-1}\) is the mean squared error from the previous iteration.
- Parameters:
a (float, optional) – Scaling factor. Default: 0.01
mse (float, optional) – Initial MSE value. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DLReLU(a=0.02, mse=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DLReLU(learnable=True, inplace=True) >>> m.update_mse(0.3) # Update MSE value >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DPAF(a: float = 1.0, m: float = 0.0, base_activation: ~typing.Callable = <function relu>, learnable: bool = False, inplace: bool = False)[source]
Applies the Dual Parametric Activation Function:
\(\text{DPAF}(x) = \begin{cases} a \cdot g(x) + m, & x \geq 0 \\ g(x) + m, & x < 0 \end{cases}\)
where \(g(x)\) is a base activation function.
- Parameters:
a (float, optional) – Scaling factor for positive values. Default: 1.0
m (float, optional) – Bias term. Default: 0.0
base_activation (callable, optional) – Base activation function. Default:
torch.nn.functional.relulearnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DPAF(a=1.5, m=0.1, base_activation=torch.tanh) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DPAF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DPReLU(a: float = 1.0, b: float = 0.01, learnable: bool = False, inplace: bool = False)[source]
Applies the Dual Parametric ReLU function:
\(\text{DPReLU}(x) = \begin{cases} a \cdot x, & x \geq 0 \\ b \cdot x, & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor for positive values. Default: 1.0
b (float, optional) – Scaling factor for negative values. Default: 0.01
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DPReLU(a=1.0, b=0.01) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DPReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DReLU(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Dynamic ReLU function:
\(\text{DReLU}(x) = \begin{cases} x, & x - a \geq 0 \\ a, & x - a < 0 \end{cases}\)
- Parameters:
a (float, optional) – Threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DReLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DerivativeOfSiLU[source]
Applies the Derivative of SiLU activation function:
\(\text{DerivativeOfSiLU}(z) = \sigma(z) \cdot (1 + z \cdot (1 - \sigma(z)))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DerivativeOfSigmoidFunction[source]
Applies the Derivative of Sigmoid Function activation:
\(\text{DerivativeOfSigmoidFunction}(z) = \exp(-z) \cdot (\sigma(z))^2\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSigmoidFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DifferenceELU(a: float = 1.0, b: float = 1.0)[source]
Applies the Difference ELU activation function:
\(\text{DifferenceELU}(z) = \begin{cases} z, & z \geq 0 \\ a(z\exp(z) - b\exp(bz)), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DifferenceELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DoubleSiLU[source]
Applies the Double SiLU activation function:
\(\text{DoubleSiLU}(z) = z \cdot \frac{1}{1 + \exp\left(-z \cdot \frac{1}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DoubleSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.DualLine(a: float = 1.0, b: float = 0.01, m: float = -0.22, learnable: bool = False, inplace: bool = False)[source]
Applies the Dual Line activation function:
\(\text{DualLine}(x) = \begin{cases} a \cdot x + m, & x \geq 0 \\ b \cdot x + m, & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Slope for positive values. Default: 1.0
b (float, optional) – Slope for negative values. Default: 0.01
m (float, optional) – Bias term. Default: -0.22
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.DualLine(a=1.0, b=0.01, m=-0.22) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.DualLine(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.EDELU(a: float = 1.0, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Extended Exponential Linear Unit function:
- :math:`text{EDELU}(x) = begin{cases}
x, & x geq c \ frac{exp(a cdot x) - 1}{b}, & x < c
end{cases}`
where \(b \cdot c = \exp(a \cdot c) - 1\) to ensure continuity at \(x = c\).
- Parameters:
a (float, optional) – Exponential parameter. Default: 1.0
c (float, optional) – Threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.EDELU(a=1.0, c=0.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.EDELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.EELU(a: float = 1.0, b: float = 1.0, epsilon: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the Elastic Exponential Linear Unit function:
- :math:`text{EELU}(x) = begin{cases}
k cdot x, & x geq 0 \ a cdot (exp(b cdot x) - 1), & x < 0
end{cases}`
where \(k \sim \text{truncated } N(1, \sigma^2)\) and \(\sigma \sim U(0, \epsilon)\).
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
b (float, optional) – Exponential parameter for negative values. Default: 1.0
epsilon (float, optional) – Upper bound for uniform distribution. Default: 0.5
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.EELU(a=1.0, b=1.0, epsilon=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.EELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.EPReLU(a: float = 1.0, alpha: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the Elastic PReLU function:
\(\text{EPReLU}(x) = \begin{cases} k \cdot x, & x \geq 0 \\ \frac{x}{a}, & x < 0 \end{cases}\)
where \(k \sim U(1 - \alpha, 1 + \alpha)\) is sampled from a uniform distribution.
- Parameters:
a (float, optional) – Scaling factor for negative values. Default: 1.0
alpha (float, optional) – Range parameter for the uniform distribution. Default: 0.1
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.EPReLU(a=0.5, alpha=0.2) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.EPReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ESwish(a: float = 1.5, learnable: bool = False, inplace: bool = False)[source]
Applies the E-Swish activation function:
\(\text{E-swish}(x) = a \cdot x \cdot \sigma(x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Scaling parameter, recommended in range [1, 2]. Default: 1.5
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ESwish(a=1.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ESwish(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.EfficientAsymmetricNonlinearActivationFunction[source]
Applies the Efficient Asymmetric Nonlinear Activation Function:
\(\text{EfficientAsymmetricNonlinearActivationFunction}(z) = z \cdot \frac{\exp(z)}{\exp(z) + 2}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = EfficientAsymmetricNonlinearActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ElasticAdaptivelyParametricCompoundedUnit(a: float = 1.0, b: float = 1.0, num_parameters: int = 1)[source]
Applies the Elastic Adaptively Parametric Compounded Unit activation function:
\(\text{ElasticAdaptivelyParametricCompoundedUnit}(z_i) = \begin{cases} b_i z_i, & z_i \geq 0 \\ a_i z_i \cdot \tanh(\ln(1 + \exp(a_{i}z_{i}))), & z_i < 0 \end{cases}\)
- Parameters:
a (float or Tensor, optional) – Negative slope parameter. Default: 1.0
b (float or Tensor, optional) – Positive slope parameter. Default: 1.0
num_parameters (int, optional) – Number of parameters if using per-channel parameterization. Default: 1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ElasticAdaptivelyParametricCompoundedUnit(a=0.5, b=1.5) >>> x = torch.randn(2) >>> output = m(x) >>> # Per-channel parameterization >>> m = ElasticAdaptivelyParametricCompoundedUnit(num_parameters=3) >>> x = torch.randn(3, 5) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ElliottActivationFunction[source]
Applies the Elliott Activation Function:
\(\text{ElliottActivationFunction}(z) = \frac{0.5z}{1 + |z|} + 0.5\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ElliottActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ErfAct(a: float = 1.0, b: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the ErfAct activation function:
\(\text{ErfAct}(x) = x \cdot \text{erf}(a \cdot \exp(b \cdot x))\)
where \(\text{erf}(x)\) is the error function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
b (float, optional) – Parameter controlling the exponential growth. Default: 0.5
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ErfAct(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ErfAct(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ErfReLU(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Erf-based ReLU function:
- :math:`text{ErfReLU}(x) = begin{cases}
x, & x geq 0 \ a cdot text{erf}(x), & x < 0
end{cases}`
where \(\text{erf}(x)\) is the error function.
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ErfReLU(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ErfReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ExpDLReLU(a: float = 0.01, mse: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Exponential Dynamic Leaky ReLU function:
\(\text{exp-DLReLU}(x) = \begin{cases} x, & x \geq 0 \\ a \cdot c_t \cdot x, & x < 0 \end{cases}\)
where \(c_t = \exp(-\text{MSE}_{t-1})\) is the exponential of the negative mean squared error from the previous iteration.
- Parameters:
a (float, optional) – Scaling factor. Default: 0.01
mse (float, optional) – Initial MSE value. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ExpDLReLU(a=0.02, mse=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ExpDLReLU(learnable=True, inplace=True) >>> m.update_mse(0.3) # Update MSE value >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ExpExpish[source]
Applies the ExpExpish activation function:
\(\text{ExpExpish}(z) = z \cdot \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExpExpish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ExponentialLinearSigmoidSquashing[source]
Applies the Exponential Linear Sigmoid Squashing activation function:
\(\text{ExponentialLinearSigmoidSquashing}(z) = \begin{cases} \frac{z}{1 + \exp(-z)}, & z \geq 0 \\ \frac{\exp(z) - 1}{1 + \exp(-z)}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ExponentialSwish[source]
Applies the Exponential Swish activation function:
\(\text{ExponentialSwish}(z) = \exp(-z) \cdot \sigma(z)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FCAF_Hidden(r: float = 4.0, a: float = 0.0, b: float = 0.5, iterations: int = 1)[source]
Applies the Fusion of Chaotic Activation Function for hidden units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i)\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Hidden() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Hidden(r=3.9, a=0.1, b=0.3, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FCAF_Output(r: float = 4.0, a: float = 0.0, b: float = 0.5, c: float = 1.0, d: float = 0.0, iterations: int = 1)[source]
Applies the Fusion of Chaotic Activation Function for output units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i) + \exp(-cz_i^2) + d\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5c (float, optional) – Gaussian width parameter. Default:
1.0d (float, optional) – Constant shift parameter. Default:
0.0iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Output() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Output(r=3.9, a=0.1, b=0.3, c=2.0, d=0.1, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FELU(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Fast Exponential Linear Unit function:
- :math:`text{FELU}(x) = begin{cases}
x, & x geq 0 \ a cdot 2^{frac{x}{ln(2)}} - 1, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FELU(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FPAF(a: float = 1.0, b: float = 1.0, pos_activation: ~typing.Callable = <function relu>, neg_activation: ~typing.Callable = <function relu>, learnable: bool = False)[source]
Applies the Fully Parameterized Activation Function:
\(\text{FPAF}(x) = \begin{cases} a \cdot g_1(x), & x \geq 0 \\ b \cdot g_2(x), & x < 0 \end{cases}\)
where \(g_1(x)\) and \(g_2(x)\) are base activation functions.
- Parameters:
a (float, optional) – Scaling factor for positive values. Default: 1.0
b (float, optional) – Scaling factor for negative values. Default: 1.0
pos_activation (callable, optional) – Activation for positive values. Default:
torch.nn.functional.reluneg_activation (callable, optional) – Activation for negative values. Default:
torch.nn.functional.relulearnable (bool, optional) – optionally make parameters trainable. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FPAF(a=1.0, b=0.5, pos_activation=torch.tanh, neg_activation=torch.sigmoid) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FPAF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FReLU(b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Flexible ReLU function:
\(\text{FReLU}(x) = \text{ReLU}(x) + b = \begin{cases} x + b, & x \geq 0 \\ b, & x < 0 \end{cases}\)
- Parameters:
b (float, optional) – Bias parameter. Default: 0.0
learnable (bool, optional) – optionally make
btrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FReLU(b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FSA(rank=5, init_a=0.0, init_b=0.1, init_c=0.1, init_d=1.0)[source]
Applies the Fourier Series Activation (FSA) function:
\(\text{FSA}(z_i) = a_i + \sum_{j=1}^{r} (b_{i,j} \cos(jd_i z_i) + c_{i,j} \sin(jd_i z_i))\)
where \(a_i\), \(b_{i,j}\), \(c_{i,j}\), \(d_i\) are trainable parameters, and \(r\) is a fixed hyperparameter denoting the rank of the Fourier series.
- Parameters:
rank (int, optional) – Rank of the Fourier series (r). Default: 5
init_a (float, optional) – Initial value for the bias parameter a. Default: 0.0
init_b (float, optional) – Initial value for the cosine coefficients b. Default: 0.1
init_c (float, optional) – Initial value for the sine coefficients c. Default: 0.1
init_d (float, optional) – Initial value for the frequency parameter d. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = FSA(rank=5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.FasterPowerFunctionLinearUnit[source]
Applies the Faster Power Function Linear Unit activation function:
\(\text{FasterPowerFunctionLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ z + \frac{z^2}{\sqrt{1 + z^2}}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = FasterPowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.GABU(activation_pool=None, init_gates=0.0)[source]
Applies the Gating Adaptive Blending Unit (GABU) function:
\(\text{GABU}(z_i) = \sum_{j=0}^{n} \sigma(a_{j,i}) g_j(z_i)\)
where \(g_j\) are activation functions from a pool, \(\sigma\) is the logistic sigmoid function, and \(a_{j,i}\) are trainable parameters controlling the weight of each activation function.
- Parameters:
activation_pool (list, optional) – List of activation functions to blend. Default: [nn.Tanh(), nn.ReLU(), nn.SiLU(), nn.Identity()]
init_gates (float, optional) – Initial value for the gating parameters. Default: 0.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GABU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.GaussianErrorLinearUnit[source]
Applies the Gaussian Error Linear Unit activation function:
\(\text{GELU}(z) = z \cdot \Phi(z) = z \cdot \frac{1}{2} \left( 1 + \text{erf}\left(\frac{z}{\sqrt{2}}\right) \right)\)
This is a wrapper around PyTorch’s native F.gelu implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GaussianErrorLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.GeneralizedHyperbolicTangent(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Generalized Hyperbolic Tangent function:
\(\text{GeneralizedHyperbolicTangent}(x) = a \cdot \frac{1 - \exp(-b \cdot x)}{1 + \exp(-b \cdot x)}\)
- Parameters:
a (float, optional) – Amplitude parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.GeneralizedHyperbolicTangent(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.GeneralizedHyperbolicTangent(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.GeneralizedSwish[source]
Applies the Generalized Swish activation function:
\(\text{GSwish}(z) = z \cdot \sigma(\exp(-z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GeneralizedSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Gish[source]
Applies the Gish activation function:
\(\text{Gish}(z) = z \cdot \ln(2 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Gish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HPAF(order=5, init_a=0.1)[source]
Applies the Hermite Polynomial-based Activation Function (HPAF):
\(\text{HPAF}(z) = \sum_{j=0}^{k} a_j H_j(z)\)
where \(a_j\) are learnable parameters, \(k\) is a fixed hyperparameter denoting the maximum order of used Hermite polynomials, and \(H_j(z)\) is a Hermite polynomial of order j.
- Parameters:
order (int, optional) – Maximum order of Hermite polynomials. Default: 5
init_a (float, optional) – Initial value for the coefficients. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HPAF(order=5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HardExponentialLinearSigmoidSquashing[source]
Applies the Hard Exponential Linear Sigmoid Squashing activation function:
\(\text{HardExponentialLinearSigmoidSquashing}(z) = \begin{cases} z \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z \geq 0 \\ (1 + \exp(-z)) \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HardSReLUE(a: float = 1.0)[source]
Applies the Hard SReLUE activation function:
\(\text{HardSReLUE}(z) = \begin{cases} az \cdot \max\left(0, \min\left(1, \frac{z+1}{2} + z\right)\right), & z \geq 0 \\ a(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardSReLUE(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HardSigmoid(version: str = 'v1', inplace: bool = False)[source]
Applies the Hard Sigmoid activation function:
\(\text{HardSigmoid}(z) = \max(0, \min(\frac{z+1}{2}, 1))\)
or alternatively:
\(\text{HardSigmoid}(z) = \max(0, \min(0.2z + 0.5, 1))\)
- Parameters:
version (str, optional) – Version of hard sigmoid to use (‘v1’ or ‘v2’). Default:
'v1'inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.HardSigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSigmoid(version='v2', inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HardSwish(inplace: bool = False)[source]
Applies the Hard Swish activation function:
\[\begin{split}\text{Hard swish}(z) = z \cdot \begin{cases} 0, & z \leq -3, \\ 1, & z \geq 3, \\ \frac{z}{6} + \frac{1}{2}, & -3 < z < 3, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.HardSwish() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSwish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HardTanh(a: float = -1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the HardTanh activation function:
\[\begin{split}\text{HardTanh}(z) = \begin{cases} a, & z < a, \\ z, & a \leq z \leq b, \\ b, & z > b, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Lower bound of the linear region. Default:
-1.0b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.HardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardTanh(a=-2.0, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Hardshrink(a: float = 0.5, inplace: bool = False)[source]
Applies the Hardshrink activation function:
\[\begin{split}\text{Hardshrink}(z) = \begin{cases} z, & z > a, \\ 0, & -a \leq z \leq a, \\ z, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.Hardshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Hardshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Hat(a: float = 2.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Hat activation function:
- :math:`text{Hat}(x) = begin{cases}
0, & x < 0 \ x, & 0 leq x leq frac{a}{2} \ a - x, & frac{a}{2} leq x leq a \ 0, & x > a
end{cases}`
- Parameters:
a (float, optional) – Width parameter of the hat. Default: 2.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.Hat(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Hat(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Hexpo(a: float = 1.0, b: float = 1.0, c: float = 1.0, d: float = 1.0, inplace: bool = False)[source]
Applies the Hexpo activation function:
\(\text{Hexpo}(z) = \begin{cases} -a \exp\left(-\frac{z}{b}\right) - 1, & z \geq 0 \\ c \exp\left(-\frac{z}{d}\right) - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Positive scale parameter. Default: 1.0
b (float, optional) – Positive decay parameter. Default: 1.0
c (float, optional) – Negative scale parameter. Default: 1.0
d (float, optional) – Negative decay parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Hexpo(a=1.5, b=0.5, c=2.0, d=0.7) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Hexpo(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.HyperbolicTangentSiLU[source]
Applies the Hyperbolic Tangent SiLU activation function:
\(\text{HyperbolicTangentSiLU}(z) = \frac{\exp\left(\frac{z}{1 + \exp(-z)}\right) - \exp\left(-\frac{z}{1 + \exp(-z)}\right)}{\exp\left(\frac{z}{1 + \exp(-z)}\right) + \exp\left(\frac{z}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HyperbolicTangentSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ISRLU(a: float = 1.0, inplace: bool = False)[source]
Applies the ISRLU (Inverse Square Root Linear Unit) activation function:
\(\text{ISRLU}(z) = \begin{cases} z, & z \geq 0 \\ \frac{z}{\sqrt{1 + az^2}}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ISRU(a: float = 1.0, inplace: bool = False)[source]
Applies the ISRU (Inverse Square Root Unit) activation function:
\(\text{ISRU}(z) = \frac{z}{\sqrt{1 + az^2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ImprovedLogisticSigmoid(a: float = 0.2, b: float = 2.0, inplace: bool = False)[source]
Applies the Improved Logistic Sigmoid activation function:
\(\text{ImprovedLogisticSigmoid}(z) = \begin{cases} a(z-b) + \sigma(b), & z \geq b \\ \sigma(z), & -b < z < b \\ a(z+b) + \sigma(-b), & z \leq -b \end{cases}\)
- Parameters:
a (float, optional) – Slope parameter. Default: 0.2
b (float, optional) – Threshold parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ImprovedLogisticSigmoid(a=0.1, b=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ImprovedLogisticSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.InversePolynomialLinearUnit(a: float = 1.0)[source]
Applies the Inverse Polynomial Linear Unit activation function:
\(\text{InversePolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 + |z|^a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = InversePolynomialLinearUnit(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LAAF(activation: str = 'sigmoid', a_init: float = 1.0, leaky_slope: float = 0.01, fixed_n: float = 1.0, inplace: bool = False)[source]
Applies the Locally Adaptive Activation Function (LAAF):
\(\text{LAAF}(x) = g(a \cdot x)\)
where \(a\) is a trainable parameter for each neuron and \(g\) is any activation function.
See: https://doi.org/10.1016/j.cma.2020.113028
- Parameters:
activation (str, optional) – The activation function to use. Options: ‘sigmoid’, ‘tanh’, ‘relu’, ‘leaky_relu’. Default: ‘sigmoid’
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
leaky_slope (float, optional) – Leakiness parameter for LeakyReLU. Default: 0.01
fixed_n (float, optional) – Fixed parameter to accelerate convergence. If > 1, applies g(n*a*x). Default: 1.0
inplace (bool, optional) – Can optionally do the operation in-place when possible. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LAAF(activation='tanh', a_init=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = LAAF(activation='relu', fixed_n=2.0, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LAU(a_init: float = 1.0, b_init: float = 1.0)[source]
Applies the Logmoid Activation Unit function:
\(\text{LAU}(x) = x \cdot \ln(1 + a \cdot \sigma(b \cdot x))\)
where \(a\) and \(b\) are trainable parameters and \(\sigma\) is the sigmoid function.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
b_init (float, optional) – Initial value for the trainable parameter b. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LAU(a_init=2.0, b_init=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LPAF(k=3, init_a=0.1)[source]
Applies the Legendre Polynomial-based Activation Function (LPAF):
\(\text{LPAF}(z) = \sum_{j=0}^{k} a_j G_j(z)\)
where \(a_j\) are learnable parameters, \(k\) is a fixed hyperparameter denoting the maximum order of used Legendre polynomials, and \(G_j(z)\) is a Legendre polynomial of order j.
- Parameters:
k (int, optional) – Maximum order of Legendre polynomials. Default: 3
init_a (float, optional) – Initial value for the coefficients. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LPAF(k=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LPSELU(a: float = 1.0, b: float = 1.0, c: float = 0.01, learnable: bool = False, inplace: bool = False)[source]
Applies the Leaky Parametric Scaled Exponential Linear Unit function:
- :math:`text{LPSELU}(x) = begin{cases}
a cdot x, & x geq 0 \ a cdot b cdot (exp(x) - 1) + c cdot x, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Scale parameter for exponential term. Default: 1.0
c (float, optional) – Scale parameter for linear term in negative region. Default: 0.01
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.LPSELU(a=1.0, b=1.0, c=0.01) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LPSELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LPSELU_RP(a: float = 1.0, b: float = 1.0, c: float = 0.01, m: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Leaky Parametric Scaled Exponential Linear Unit with Reposition Parameter function:
- :math:`text{LPSELU_RP}(x) = begin{cases}
a cdot x + m, & x geq 0 \ a cdot b cdot (exp(x) - 1) + c cdot x + m, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Scale parameter for exponential term. Default: 1.0
c (float, optional) – Scale parameter for linear term in negative region. Default: 0.01
m (float, optional) – Reposition parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.LPSELU_RP(a=1.0, b=1.0, c=0.01, m=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LPSELU_RP(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LReLU(a: float = 100.0, inplace: bool = False)[source]
Applies the Leaky ReLU activation function.
\[\begin{split}\text{LReLU}(z) = \begin{cases} z, & z \geq 0, \\ \frac{z}{a}, & z < 0, \end{cases}\end{split}\]where \(a\) is recommended to be 100.
- Parameters:
a (float, optional) – The denominator for negative inputs. Default:
100.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
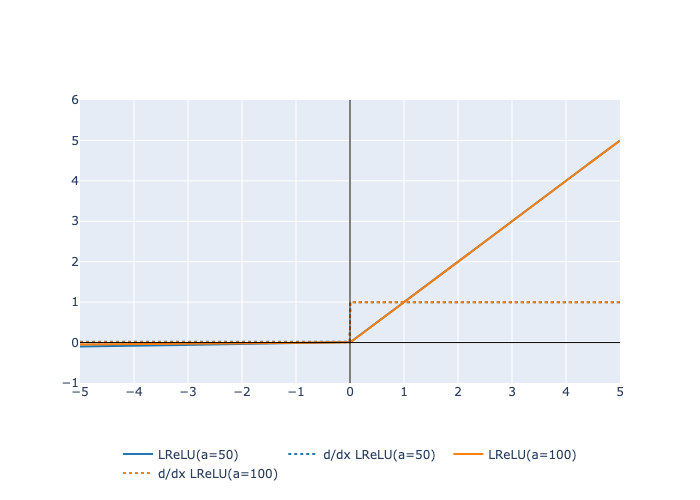
Examples:
>>> m = torch_activation.LReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LReLU(a=50.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LSPTLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Linear Symmetric Piecewise Triangular Linear Unit activation function:
\[\begin{split}\text{LSPTLU}(z) = \begin{cases} 0.2z, & z < 0, \\ z, & 0 \leq z \leq a, \\ 2a - z, & a < z \leq 2a, \\ 0, & z > 2a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the shape. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.LSPTLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LSPTLU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LSReLU(a: float = 1.0, b: float = 1.0)[source]
Applies the LSReLU activation function:
\(\text{LSReLU}(z) = \begin{cases} \frac{z}{1 + |z|}, & z \leq 0 \\ z, & 0 \leq z \leq b \\ \log(az + 1) + |\log(ab + 1) - b|, & z \geq b \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > b. Default: 1.0
b (float, optional) – Threshold parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LSReLU(a=0.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LaplaceLinearUnit[source]
Applies the Laplace Linear Unit activation function:
\(\text{LaLU}(z) = z \cdot \Phi_{\text{Laplace}}(z) = z \cdot \begin{cases} 1 - \frac{1}{2} \exp(-z), & z \geq 0 \\ \frac{1}{2} \exp(z), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LaplaceLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LeLeLU(a: float = 1.0, negative_slope: float = 0.01, learnable: bool = False, inplace: bool = False)[source]
Applies the Leaky Learnable ReLU activation function:
\(\text{LeLeLU}(x) = \begin{cases} a \cdot x, & x \geq 0 \\ 0.01 \cdot a \cdot x, & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor. Default: 1.0
negative_slope (float, optional) – Controls the slope of the negative part. Default: 0.01
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.LeLeLU(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LeLeLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LeakyScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 0.1)[source]
Applies the Leaky Scaled Exponential Linear Unit activation function:
\(\text{LeakyScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1) + acz, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Leaky slope. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LeakyScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LiSA(ar: float = 1.0, al: float = 0.1)[source]
Applies the Linearized Sigmoidal Activation (LiSA) function:
\(\text{LiSA}(z_i) = \begin{cases} a^r z_i - a^r + 1, & z_i \geq 1 \\ z_i, & 1 > z_i > 0 \\ a^l z_i, & z_i \leq 0 \end{cases}\)
where \(a^r\) and \(a^l\) are fixed parameters.
- Parameters:
ar (float, optional) – Fixed value for the right slope parameter ar. Default: 1.0
al (float, optional) – Fixed value for the left slope parameter al. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LiSA(ar=1.0, al=0.1) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LinQ(a: float = 1.0, inplace: bool = False)[source]
Applies the LinQ (Linear Quadratic) activation function:
\(\text{LinQ}(z) = \begin{cases} az + 1 - 2z + z^2, & z \geq 2 - 2a \\ \frac{1}{4}z(4 - |z|), & -2 + 2a < z < 2 - 2a \\ az - 1 - 2z + z^2, & z \leq -2 + 2a \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LinQ(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LinQ(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LinearlyScaledHyperbolicTangent[source]
Applies the Linearly Scaled Hyperbolic Tangent activation function:
\(\text{LinearlyScaledHyperbolicTangent}(z) = z \cdot \tanh(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LinearlyScaledHyperbolicTangent() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LipschitzReLU(p_fn=None, n_fn=None)[source]
Applies the Lipschitz ReLU activation function:
\(\text{LipschitzReLU}(z) = p(z | z > 0) + n(z | z \leq 0)\)
where p and n are positive and negative functions with Lipschitz constant <= 1.
- Parameters:
p_fn (callable, optional) – Positive function. Default: identity
n_fn (callable, optional) – Negative function. Default: zero
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> # Default implementation (standard ReLU) >>> m = LipschitzReLU() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom implementation with leaky behavior >>> m = LipschitzReLU(p_fn=lambda x: x, n_fn=lambda x: 0.1 * x) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LogLog[source]
Applies the LogLog activation function:
\(\text{LogLog}(z) = \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LogLogish[source]
Applies the LogLogish activation function:
\(\text{LogLogish}(z) = z \cdot (1 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogLogish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LogSQNL(inplace: bool = False)[source]
Applies the LogSQNL (Logarithmic Square Non-Linear) activation function:
\(\text{LogSQNL}(z) = \begin{cases} 1, & z > 2 \\ \frac{1}{2}z - \frac{z^2}{4} + \frac{1}{2}, & 0 \leq z \leq 2 \\ \frac{1}{2}z + \frac{z^2}{4} + \frac{1}{2}, & -2 \leq z < 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogSQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LogSQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.LogSigmoid[source]
Applies the LogSigmoid activation function:
\(\text{LogSigmoid}(z) = \ln(\sigma(z)) = \ln\left(\frac{1}{1 + \exp(-z)}\right)\)
This is a wrapper around PyTorch’s native F.logsigmoid implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Logish[source]
Applies the Logish activation function:
\(\text{Logish}(z) = z \cdot \ln(1 + \sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Logish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MEF(inplace: bool = False)[source]
Applies the MEF (Modified Error Function) activation function:
\(\text{MEF}(z) = \frac{z}{\sqrt{1 + z^2} + 2}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MEF() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.MEF(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MPELU(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Multiple Parametric Exponential Linear Unit function:
- :math:`text{MPELU}(x) = begin{cases}
x, & x geq 0 \ a cdot (exp(b cdot x) - 1), & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
b (float, optional) – Exponential parameter for negative values. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.MPELU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.MPELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MReLU(inplace: bool = False)[source]
Applies the Mirrored Rectified Linear Unit activation function:
\[\begin{split}\text{mReLU}(z) = \min(\text{ReLU}(1 - z), \text{ReLU}(1 + z)) = \begin{cases} 1 + z, & -1 \leq z \leq 0, \\ 1 - z, & 0 < z \leq 1, \\ 0, & \text{otherwise}, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.MReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.MReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MarReLU(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Margin ReLU activation function:
\(\text{MarReLU}(x) = \max(x, a) = \begin{cases} x, & x - a \geq 0 \\ a, & x - a < 0 \end{cases}\)
- Parameters:
a (float, optional) – Margin threshold. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.MarReLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.MarReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Minsin(inplace: bool = False)[source]
Applies the element-wise function:
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:

Examples:
>>> m = Minsin() >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Mish[source]
Applies the Mish activation function:
\(\text{Mish}(z) = z \cdot \tanh(\text{softplus}(z)) = z \cdot \tanh(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Mish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MoGU(n_gaussians=3, init_a=1.0, init_sigma=1.0, init_mu_spread=2.0)[source]
Applies the Mixture of Gaussian Unit (MoGU) function:
\(\text{MoGU}(z_i) = \sum_{j=0}^{n} a_{i,j} \frac{1}{\sqrt{2\pi\sigma_{i,j}^2}} \exp\left(-\frac{(z_i-\mu_{i,j})^2}{2\sigma_{i,j}^2}\right)\)
where \(a_{i,j}\), \(\sigma_{i,j}\), and \(\mu_{i,j}\) are trainable parameters.
- Parameters:
n_gaussians (int, optional) – Number of Gaussian components in the mixture. Default: 3
init_a (float, optional) – Initial value for the scale parameters a. Default: 1.0
init_sigma (float, optional) – Initial value for the standard deviation parameters sigma. Default: 1.0
init_mu_spread (float, optional) – Spread for initializing the mean parameters mu. Default: 2.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = MoGU(n_gaussians=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ModifiedComplementaryLogLog[source]
Applies the Modified Complementary LogLog activation function:
\(\text{ModifiedComplementaryLogLog}(z) = 1 - 2\exp(-0.7\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ModifiedComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ModifiedSiLU[source]
Applies the Modified SiLU activation function:
\(\text{ModifiedSiLU}(z) = z \cdot \sigma(z) + \exp\left(-\frac{z^2}{4}\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ModifiedSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.MultistateActivationFunction(a: float = 0.0, b: list = None)[source]
Applies the Multistate Activation Function:
\(\text{MultistateActivationFunction}(z) = a + \sum_{k=1}^N \frac{1}{1 + \exp(-z+b_k)}\)
- Parameters:
a (float, optional) – Offset parameter. Default: 0.0
b (list of float, optional) – List of shift parameters. Default: [1.0, 2.0]
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MultistateActivationFunction(a=0.5, b=[0.5, 1.5, 2.5]) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.NActivation(init_a: float = -0.5, init_b: float = 0.5)[source]
Applies the N-Activation function:
\(\text{N-Activation}(z_i) = \begin{cases} z_i - 2t_{i,min}, & z_i < t_{i,min} \\ -z_i, & t_{i,min} \leq z_i \leq t_{i,max} \\ z_i - 2t_{i,max}, & z_i > t_{i,max} \end{cases}\)
where \(t_{i,min} = \min(a_i, b_i)\) and \(t_{i,max} = \max(a_i, b_i)\), and \(a_i\) and \(b_i\) are trainable parameters.
- Parameters:
init_a (float, optional) – Initial value for parameter a. Default: -0.5
init_b (float, optional) – Initial value for parameter b. Default: 0.5
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = NActivation(init_a=-0.5, init_b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.NLReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Natural-Logarithm-ReLU activation function:
\(\text{NLReLU}(z) = \ln(a \cdot \max(0, z) + 1)\)
- Parameters:
a (float, optional) – Scaling factor for the ReLU output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
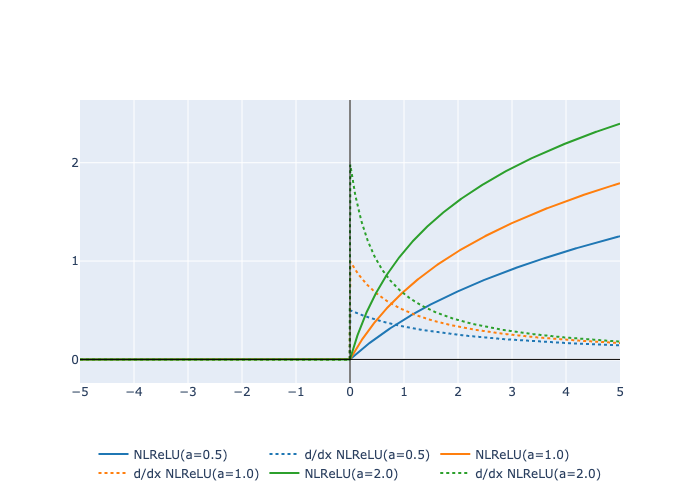
Examples:
>>> m = torch_activation.NLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NLReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.NReLU(sigma: float = 0.1, inplace: bool = False)[source]
Applies the Noisy ReLU activation function.
\[\text{NReLU}(z) = \max(0, z + a)\]where \(a \sim N(0, \sigma(z))\) is sampled from a Gaussian distribution.
- Parameters:
sigma (float, optional) – Standard deviation for the noise. Default:
0.1inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
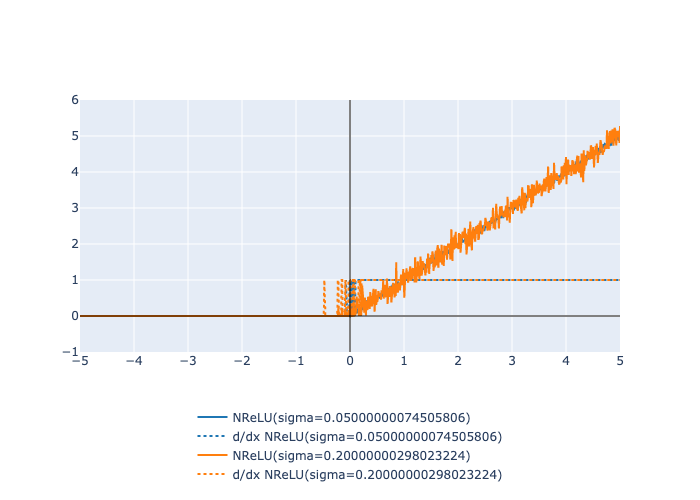
Examples:
>>> m = torch_activation.NReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NReLU(sigma=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.NewSigmoid[source]
Applies the New Sigmoid activation function:
\(\text{NewSigmoid}(z) = \frac{\exp(z) - \exp(-z)}{2(\exp(2z) + \exp(-2z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.NewSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PATS(a: float = 0.625, lower_bound: float = 0.5, upper_bound: float = 0.75, learnable: bool = False, inplace: bool = False)[source]
Applies the PATS activation function:
\(\text{PATS}(x) = x \cdot \arctan(a \cdot \pi \cdot \sigma(x))\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 0.625
lower_bound (float, optional) – Lower bound for sampling a. Default: 0.5
upper_bound (float, optional) – Upper bound for sampling a. Default: 0.75
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PATS(a=0.625) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PATS(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PDELU(a: float = 1.0, b: float = 0.9, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Deformable Exponential Linear Unit function:
- :math:`text{PDELU}(x) = begin{cases}
x, & x geq 0 \ a cdot left[1 + (1 - b) cdot xright]^{frac{1}{1 - b}} - 1, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Deformation parameter. Default: 0.9
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PDELU(a=1.0, b=0.9) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PDELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PE2Id(a: float = 0.5, elu_alpha: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the P-E2-Id function:
\(\text{P-E2-Id}(x) = a \cdot x + (1 - a) \cdot (\text{ELU}(x) - \text{ELU}(-x))\)
- Parameters:
a (float, optional) – Weight for identity component. Default: 0.5
elu_alpha (float, optional) – Alpha parameter for ELU. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PE2Id(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PE2Id(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PE2ReLU(a: float = 0.4, b: float = 0.3, elu_alpha: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the P-E2-ReLU function:
\(\text{P-E2-ReLU}(x) = a \cdot \text{ReLU}(x) + b \cdot \text{ELU}(x) + (1 - a - b) \cdot (-\text{ELU}(-x))\)
- Parameters:
a (float, optional) – Weight for ReLU component. Default: 0.4
b (float, optional) – Weight for ELU component. Default: 0.3
elu_alpha (float, optional) – Alpha parameter for ELU. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PE2ReLU(a=0.4, b=0.3) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PE2ReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PELU(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Exponential Linear Unit function:
- :math:`text{PELU}(x) = begin{cases}
frac{a}{b} cdot x, & x geq 0 \ a cdot left(expleft(frac{x}{b}right) - 1right), & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
b (float, optional) – Exponential parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PELU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PFELU(a: float = 1.0, b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the P+FELU function:
- :math:`text{P+FELU}(x) = begin{cases}
x + b, & x geq 0 \ a cdot 2^{frac{x}{ln(2)}} - 1 + b, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
b (float, optional) – Bias parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PFELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PFELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PFPLUS(a: float = 1.0, b: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric First Power Linear Unit with Sign function:
\(\text{PFPLUS}(x) = a \cdot x \cdot (1 - b \cdot x)^{H(x) - 1}\)
where \(H(x) = \begin{cases} 1, & x \geq 0 \\ 0, & x < 0 \end{cases}\) is the Heaviside step function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Shape parameter. Default: 0.1
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PFPLUS(a=1.0, b=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PFPLUS(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PREU(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Rectified Exponential Unit activation function:
\(\text{PREU}(x) = \begin{cases} a \cdot x, & x \geq 0 \\ a \cdot x \cdot \exp(b \cdot x), & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor. Default: 1.0
b (float, optional) – Exponential factor for negative values. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PREU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PREU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PReLU(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Rectified Linear Unit function:
\(\text{PReLU}(x) = \begin{cases} x, & x \geq 0 \\ \frac{x}{a}, & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor for the negative part of the input. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PReLU(a=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PReLUPlus(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Positive Parametric Rectified Linear Unit function:
\(\text{PReLU+}(x) = \begin{cases} a \cdot x, & x \geq 0 \\ 0, & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor for the positive part of the input. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PReLUPlus(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PReLUPlus(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PReNU(a: float = 0.25, inplace: bool = False)[source]
Applies the Parametric Rectified Non-linear Unit activation function:
\[\begin{split}\text{PReNU}(z) = \begin{cases} z - a \ln(z + 1), & z \geq 0, \\ 0, & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the logarithmic term. Default:
0.25inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
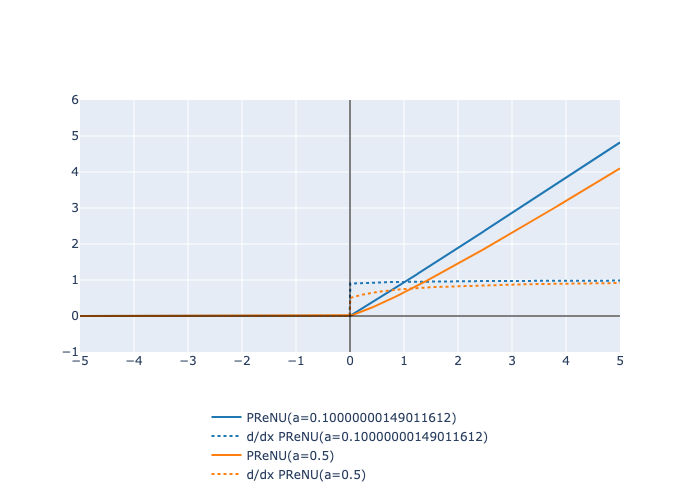
Examples:
>>> m = torch_activation.PReNU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PReNU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSELU(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Scaled Exponential Linear Unit function:
- :math:`text{PSELU}(x) = begin{cases}
a cdot x, & x geq 0 \ a cdot b cdot (exp(x) - 1), & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Scale parameter for negative values. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSELU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSF(m: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Sigmoid Function:
\(\text{PSF}(x) = \frac{1}{(1 + \exp(-x))^m}\)
- Parameters:
m (float, optional) – Power parameter. Default: 1.0
learnable (bool, optional) – optionally make
mtrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSF(m=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSGU(a: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the Parameterized Self-Circulating Gating Unit function:
\(\text{PSGU}(x) = x \cdot \tanh(a \cdot \sigma(x))\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 0.5
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSGU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSGU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSSiLU(a: float = 1.0, b: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Shifted SiLU function:
\(\text{PSSiLU}(x) = x \cdot \frac{\sigma(a \cdot x) - b}{1 - b}\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
b (float, optional) – Shift parameter. Default: 0.5
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSSiLU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSSiLU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSTanh(a_init: float = 1.0, b_init: float = 1.0)[source]
Applies the Parametric Scaled Hyperbolic Tangent function:
\(\text{PSTanh}(x) = x \cdot a \cdot (1 + \tanh(b \cdot x))\)
where \(a\) and \(b\) are trainable parameters.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
b_init (float, optional) – Initial value for the trainable parameter b. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PSTanh(a_init=2.0, b_init=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSerf(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Serf activation function:
\(\text{pserf}(x) = x \cdot \text{erf}(a \cdot \ln(1 + \exp(b \cdot x)))\)
where \(\text{erf}(x)\) is the error function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
b (float, optional) – Parameter controlling the softplus term. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSerf(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSerf(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PShELU(a: float = 1.0, b: float = 1.0, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the PELU with Horizontal Shift function:
- :math:`text{PShELU}(x) = begin{cases}
frac{a}{b} cdot (x + c), & x + c geq 0 \ a cdot left(expleft(frac{x + c}{b}right) - 1right), & x + c < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Divisive parameter. Default: 1.0
c (float, optional) – Horizontal shift parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PShELU(a=1.0, b=1.0, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PShELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSigmoid(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Sigmoid function:
\(\text{PSigmoid}(x) = a \cdot \sigma(b \cdot x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Amplitude parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSigmoid(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSigmoid(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSvELU(a: float = 1.0, b: float = 1.0, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the PELU with Vertical Shift function:
- :math:`text{PSvELU}(x) = begin{cases}
frac{a}{b} cdot x + c, & x geq 0 \ a cdot left(expleft(frac{x}{b}right) - 1right) + c, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Divisive parameter. Default: 1.0
c (float, optional) – Vertical shift parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSvELU(a=1.0, b=1.0, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSvELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PSwish(a: float = 1.0, b: float = 1.0, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Swish activation function:
- :math:`text{p-swish}(x) = begin{cases}
a cdot x cdot sigma(b cdot x), & x leq c \ x, & x > c
end{cases}`
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
b (float, optional) – Sigmoid scaling parameter. Default: 1.0
c (float, optional) – Threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PSwish(a=1.0, b=1.0, c=0.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PSwish(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PTELU(a: float = 1.0, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Tanh Exponential Linear Unit function:
\(\text{PTELU}(x) = \begin{cases} x, & x \geq 0 \\ a \cdot \tanh(b \cdot x), & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor for negative values. Default: 1.0
b (float, optional) – Scaling factor inside tanh for negative values. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PTELU(a=0.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PTELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PTaLU(a: float = -0.75, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Tangent Linear Unit function:
- :math:`text{PTaLU}(x) = begin{cases}
x, & x geq b \ tanh(x), & a < x < b \ tanh(a), & x leq a
end{cases}`
- Parameters:
a (float, optional) – Lower threshold parameter. Default: -0.75
b (float, optional) – Upper threshold parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PTaLU(a=-0.75, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PTaLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PVLU(a: float = 0.1, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Parametric Variational Linear Unit function:
\(\text{PVLU}(x) = \max(0, x) + a \cdot \sin(b \cdot x)\)
- Parameters:
a (float, optional) – Amplitude parameter for sine term. Default: 0.1
b (float, optional) – Frequency parameter for sine term. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PVLU(a=0.1, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PVLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PairedReLU(a: float = 0.5, b: float = 0.0, c: float = -0.5, d: float = 0.0, learnable: bool = False)[source]
Applies the Paired ReLU function:
\(\text{PairedReLU}(x) = \begin{pmatrix} \max(a \cdot x - b, 0) \\ \max(c \cdot x - d, 0) \end{pmatrix}\)
- Parameters:
a (float, optional) – Scaling factor for first component. Default: 0.5
b (float, optional) – Bias for first component. Default: 0.0
c (float, optional) – Scaling factor for second component. Default: -0.5
d (float, optional) – Bias for second component. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
False
- Shape:
Input: \((N, C, *)\), where \(*\) means any number of dimensions.
Output: \((N, 2*C, *)\), doubling the channel dimension.
Examples:
>>> m = torch_activation.PairedReLU(a=0.5, c=-0.5) >>> x = torch.randn(2, 3, 4, 5) >>> output = m(x) # shape: [2, 6, 4, 5] >>> m = torch_activation.PairedReLU(learnable=True) >>> x = torch.randn(2, 3) >>> output = m(x) # shape: [2, 6]
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PanFunction(a: float = 1.0, inplace: bool = False)[source]
Applies the Pan activation function:
\[\begin{split}\text{Pan function}(z) = \begin{cases} z - a, & z \geq a, \\ 0, & -a < z < a, \\ -z - a, & z \leq -a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.PanFunction() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PanFunction(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ParametricLogish(a: float = 1.0, b: float = 1.0)[source]
Applies the Parametric Logish activation function:
\(\text{ParametricLogish}(z_i) = a \cdot z_i \cdot \ln(1 + \sigma(b \cdot z_i))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ParametricLogish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ParametricSechSig(a: float = 1.0)[source]
Applies the Parametric SechSig activation function:
\(\text{ParametricSechSig}(z) = (z + a\cdot \text{sech}(z+a))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricSechSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ParametricTanhSig(a: float = 1.0)[source]
Applies the Parametric TanhSig activation function:
\(\text{ParametricTanhSig}(z) = (z + a\cdot \tanh(z+a))\sigma(z)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricTanhSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PenalizedHyperbolicTangent(a: float = 2.0, inplace: bool = False)[source]
Applies the Penalized Hyperbolic Tangent activation function:
\(\text{PenalizedHyperbolicTangent}(z) = \begin{cases} \tanh(z), & z \geq 0 \\ \frac{\tanh(z)}{a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Penalty factor for negative inputs. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.PenalizedHyperbolicTangent(a=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.PenalizedHyperbolicTangent(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Phish[source]
Applies the Phish activation function:
\(\text{Phish}(z) = z \cdot \tanh(\text{GELU}(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Phish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PiLU(a: float = 1.0, b: float = 0.01, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Piecewise Linear Unit function:
\(\text{PiLU}(x) = \begin{cases} a \cdot x + c(1 - a), & x \geq c \\ b \cdot x + c(1 - b), & x < c \end{cases}\)
- Parameters:
a (float, optional) – Slope for values above threshold. Default: 1.0
b (float, optional) – Slope for values below threshold. Default: 0.01
c (float, optional) – Threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.PiLU(a=1.0, b=0.01, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PiLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PolynomialLinearUnit[source]
Applies the Polynomial Linear Unit activation function:
\(\text{PolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 - z} - 1, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PolynomialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PowerFunctionLinearUnit[source]
Applies the Power Function Linear Unit activation function:
\(\text{PowerFunctionLinearUnit}(z) = z \cdot \frac{1}{2} \left( 1 + \frac{z}{\sqrt{1 + z^2}} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.PowerLinearUnit(a: float = 1.0)[source]
Applies the Power Linear Unit activation function:
\(\text{PowerLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ (1 - z)^{-a} - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerLinearUnit(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ProbAct(base_activation: ~typing.Callable = <function relu>, sigma: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the Probabilistic Activation function:
\(\text{ProbAct}(x) = g(x) + \sigma \cdot e\)
where \(e \sim N(0, 1)\) and \(g(x)\) is a base activation function.
- Parameters:
base_activation (callable, optional) – Base activation function. Default:
torch.nn.functional.relusigma (float, optional) – Standard deviation of the noise. Default: 0.1
learnable (bool, optional) – optionally make
sigmatrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ProbAct(sigma=0.2) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ProbAct(base_activation=torch.sigmoid, learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RMAF(a: float = 1.0, b: float = 1.0, c: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the ReLU Memristor-like Activation Function:
\(\text{RMAF}(x) = b \left(\frac{1}{0.25(1 + \exp(-x)) + 0.75}\right)^c a \cdot x\)
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
b (float, optional) – Scaling parameter. Default: 1.0
c (float, optional) – Exponent parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.RMAF(a=1.0, b=1.0, c=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RMAF(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RPReLU(a: float = 0.0, b: float = 0.0, c: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the React-PReLU activation function:
\(\text{RPReLU}(x) = \begin{cases} x - a + b, & x \geq a \\ c(x - a) + b, & x < a \end{cases}\)
- Parameters:
a (float, optional) – Threshold parameter. Default: 0.0
b (float, optional) – Bias parameter. Default: 0.0
c (float, optional) – Scaling factor for the negative part. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.RPReLU(a=0.5, b=0.1, c=0.2) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RPReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RReLU(l: float = 3.0, u: float = 8.0, inplace: bool = False)[source]
Applies the Randomized Leaky ReLU activation function.
\[\begin{split}\text{RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ z_i a_i, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled from a uniform distribution \(U(l, u)\), with recommended values \(U(3, 8)\).
- Parameters:
l (float, optional) – Lower bound of the uniform distribution. Default:
3.0u (float, optional) – Upper bound of the uniform distribution. Default:
8.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.RReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RReLU(l=2.0, u=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RSigELU(a: float = 1.0)[source]
Applies the RSigELU activation function:
\(\text{RSigELU}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \geq z \geq 1 \\ a(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELU(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RSigELUD(a: float = 1.0, b: float = 1.0)[source]
Applies the RSigELUD activation function:
\(\text{RSigELUD}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \leq z \leq 1 \\ b(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > 1. Default: 1.0
b (float, optional) – Scale parameter for z < 0. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELUD(a=1.5, b=0.8) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RTReLU(a: float = 1.0, sigma: float = 0.75, learnable: bool = False, inplace: bool = False)[source]
Applies the Randomly Translational PReLU activation function:
\(\text{RT-PReLU}(x) = \begin{cases} x, & x + b \geq 0 \\ \frac{x}{a}, & x + b < 0 \end{cases}\)
where \(b \sim N(0, \sigma^2)\)
- Parameters:
a (float, optional) – Scaling factor for the negative part. Default: 1.0
sigma (float, optional) – Standard deviation for random translation. Default: 0.75
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.RTReLU(a=0.1, sigma=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RTReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ReBLU(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Rectified Bendable Linear Unit function:
- :math:`text{ReBLU}(x) = begin{cases}
a cdot sqrt{x^2 + 1} - 1 + x, & x > 0 \ 0, & x leq 0
end{cases}`
where \(a \in [-1, 1]\) controls the bendability.
- Parameters:
a (float, optional) – Bendability parameter. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ReBLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReBLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ReLTanh(a: float = -1.5, b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Rectified Linear Tanh function:
- :math:`text{ReLTanh}(x) = begin{cases}
tanh’(a)(x - a) + tanh(a), & x leq a \ tanh(x), & a < x < b \ tanh’(b)(x - b) + tanh(b), & x geq b
end{cases}`
where \(\tanh'(x) = \frac{4}{(\exp(x) + \exp(-x))^2}\) is the derivative of tanh.
- Parameters:
a (float, optional) – Lower threshold parameter. Default: -1.5
b (float, optional) – Upper threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ReLTanh(a=-1.5, b=0.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReLTanh(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ReLUN(n: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\(\text{ReLUN}(x) = \min(\text{ReLU}(x), n)\)
- Parameters:
n (float, optional) – Upper bound for the function’s output. Default is 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.ReLUN(n=6.0) # ReLU6 >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReLUN(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ReLUProbAct(sigma: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the ReLU-based Probabilistic Activation function:
\(\text{ReLUProbAct}(x) = \max(0, x) + \sigma \cdot e\)
where \(e \sim N(0, 1)\)
- Parameters:
sigma (float, optional) – Standard deviation of the noise. Default: 0.1
learnable (bool, optional) – optionally make
sigmatrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ReLUProbAct(sigma=0.2) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReLUProbAct(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RePSU(a: float = 0.5, b: float = 0.0, c: float = 0.0, d: float = 1.0, e: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Rectified Parametric Sigmoid Unit function:
\(\text{RePSU}(x) = a \cdot \text{RePSKU}(x) + (1 - a) \cdot \text{RePSHU}(x)\)
where:
- :math:`text{RePSKU}(x) = begin{cases}
frac{x - b}{1 + expleft(-text{sgn}(x - c) frac{|x - c|^{d}}{e}right)}, & x geq b \ 0, & x < b
end{cases}`
- :math:`text{RePSHU}(x) = begin{cases}
2x - text{RePSKU}(x), & x geq b \ 0, & x < b
end{cases}`
- Parameters:
a (float, optional) – Mixing parameter. Default: 0.5
b (float, optional) – Threshold parameter. Default: 0.0
c (float, optional) – Shift parameter. Default: 0.0
d (float, optional) – Power parameter. Default: 1.0
e (float, optional) – Scale parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.RePSU(a=0.5, b=0.0, c=0.0, d=1.0, e=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RePSU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ReSP(a: float = 1.7, inplace: bool = False)[source]
Applies the Rectified Softplus activation function:
\[\begin{split}\text{ReSP}(z) = \begin{cases} az + \ln(2), & z \geq 0, \\ \ln(1 + \exp(z)), & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Scaling factor for positive inputs. Default:
1.7inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
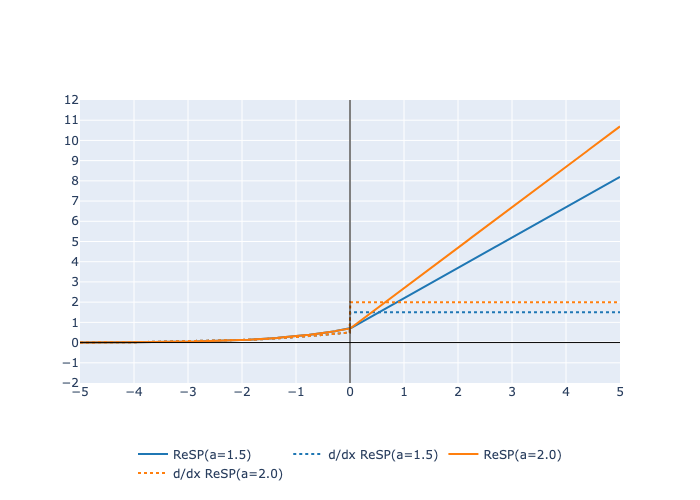
Examples:
>>> m = torch_activation.ReSP() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReSP(a=1.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RectifiedHyperbolicSecant[source]
Applies the Rectified Hyperbolic Secant activation function:
\(\text{RectifiedHyperbolicSecant}(z) = z \cdot \text{sech}(z)\)
where sech is the hyperbolic secant function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RectifiedHyperbolicSecant() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Root2sigmoid[source]
Applies the Root2sigmoid activation function:
\(\text{Root2sigmoid}(z) = \frac{\sqrt{2}z}{\sqrt{2^{-2z}} + \sqrt{2^{2z}}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Root2sigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Rootsig(a: float = 1.0)[source]
Applies the Rootsig activation function:
\(\text{Rootsig}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Rootsig(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.RowdyActivation(base_activation=None, n_terms=5, scaling_factor=1.0, init_a=0.1, use_cos=False)[source]
Applies the Rowdy Activation function, a special case of DKNN:
\(\text{Rowdy}(z_l) = g_0(z_l) + \sum_{j=1}^{n} a_j \cdot c \cdot \sin(jcz_l)\)
where \(g_0\) is a base activation function, \(c\) is a fixed scaling factor, and \(a_j\) are trainable parameters.
- Parameters:
base_activation (nn.Module, optional) – Base activation function g_0. Default: nn.ReLU()
n_terms (int, optional) – Number of sine terms to use. Default: 5
scaling_factor (float, optional) – Fixed scaling factor c. Default: 1.0
init_a (float, optional) – Initial value for the scaling parameters a. Default: 0.1
use_cos (bool, optional) – If True, uses cosine instead of sine. Default: False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RowdyActivation(n_terms=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SAU(a: float = 1.0, b: float = 1.0, learnable: bool = False)[source]
Applies the Smooth Activation Unit function:
\(\text{SAU}(x) = (\text{PReLU}_{a} * \phi_{b})(x) = \frac{1}{2b \sqrt{\pi}} \exp\left(-\frac{b^2 x^2}{2}\right) + \frac{1}{2}\left(1 - \frac{a}{x} + \frac{x \cdot \text{erf}(b x / \sqrt{2})}{2}\right)\)
- Parameters:
a (float, optional) – PReLU parameter. Default: 1.0
b (float, optional) – Smoothing parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SAU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SAU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SCMish(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Soft Clipping Mish activation function:
\(\text{SC-mish}(x) = \max(0, x \cdot \tanh(\text{softplus}(a \cdot x)))\)
- Parameters:
a (float, optional) – Scaling parameter. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SCMish(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SCMish(a=0.25) # SCL-mish variant >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SCMish(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SCSwish(inplace: bool = False)[source]
Applies the Soft Clipping Swish activation function:
\(\text{SC-swish}(x) = \max(0, x \cdot \sigma(x))\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SCSwish() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SCSwish(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SExp(a_init: float = 1.0, b_init: float = 1.0)[source]
Applies the Scaled Exponential function:
\(\text{SExp}(x) = a \cdot (\exp(b \cdot x) - 1)\)
where \(a\) and \(b\) are trainable parameters.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
b_init (float, optional) – Initial value for the trainable parameter b. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SExp(a_init=2.0, b_init=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SLAF(k=6, init_a=0.1)[source]
Applies the Self-Learnable Activation Function (SLAF):
\(\text{SLAF}(z_i) = \sum_{j=0}^{k-1} a_{i,j} z_i^j\)
where \(a_{i,j}\) are learnable parameters for each neuron and \(k\) is a hyperparameter defining the number of elements in the polynomial expression.
- Parameters:
k (int, optional) – Number of terms in the polynomial. Default: 6
init_a (float, optional) – Initial value for the coefficients. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SLAF(k=4) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SLU(inplace: bool = False)[source]
Applies the Softplus Linear Unit activation function:
\[\begin{split}\text{SLU}(z) = \begin{cases} az, & z \geq 0, \\ b \ln(\exp(z) + 1) - c, & z < 0, \end{cases}\end{split}\]which simplifies to:
\[\begin{split}\text{SLU}(z) = \begin{cases} z, & z \geq 0, \\ 2 \ln(\frac{\exp(z) + 1}{2}), & z < 0, \end{cases}\end{split}\]where \(a=1, b=2, c=2\ln(2)\).
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
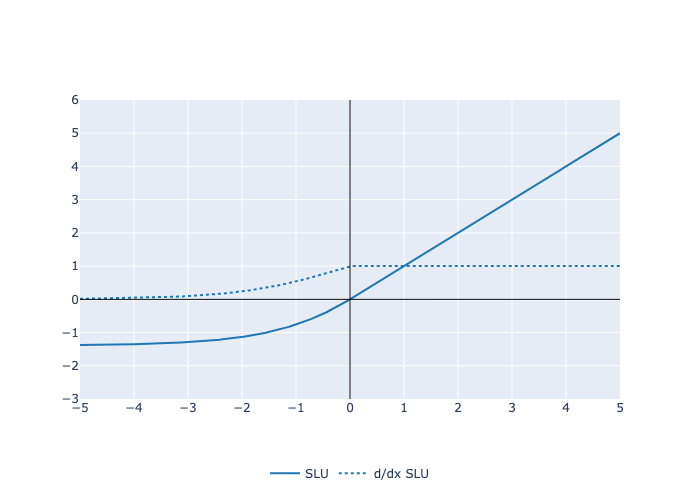
Examples:
>>> m = torch_activation.SLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SMU(a: float = 0.25, b: float = 25.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Smooth Maximum Unit activation function:
\(\text{SMU}(x) = \frac{(1 + a)x + (1 - a)x \cdot \text{erf}(b (1 - a)x)}{2}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 0.25
b (float, optional) – Smoothing parameter. Default: 25.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SMU(a=0.25, b=25.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SMU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SQLU(inplace: bool = False)[source]
Applies the SQLU (Square Linear Unit) activation function:
\(\text{SQLU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{4}, & -2 \leq z \leq 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SQMAX(c: float = 0.0, dim: int = -1)[source]
Applies the SQMAX (Square Maximum) activation function:
\(\text{SQMAX}(z_j) = \frac{(z_j + c)^2}{\sum_{k=1}^N (z_k + c)^2}\)
- Parameters:
c (float, optional) – Offset parameter. Default: 0.0
dim (int, optional) – A dimension along which SQMAX will be computed. Default: -1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQMAX(c=1.0) >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = nn.SQMAX(dim=0) >>> x = torch.randn(2, 3) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SQNL(inplace: bool = False)[source]
Applies the SQNL (Square Non-Linear) activation function:
\(\text{SQNL}(z) = \begin{cases} 1, & z > 2 \\ z - \frac{z^2}{4}, & 0 \leq z \leq 2 \\ z + \frac{z^2}{4}, & -2 \leq z < 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SRReLU(l: float = 0.125, u: float = 0.3333333333333333, inplace: bool = False)[source]
The Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}\text{S-RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ \frac{z_i}{a_i}, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
Here is a plot of the function and its derivative:
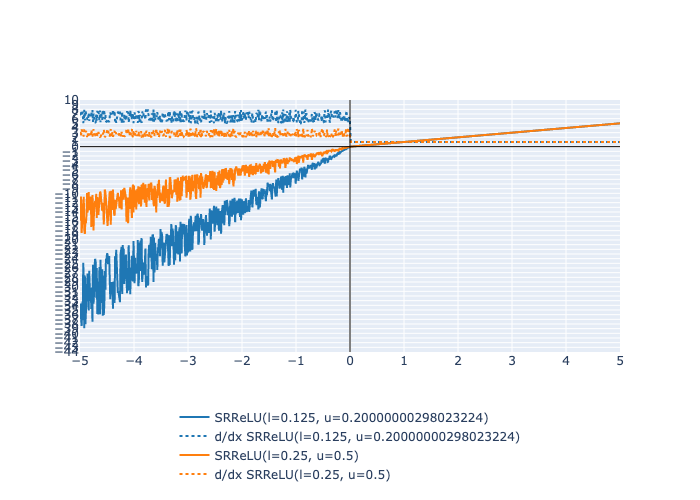
Examples:
>>> m = nn.SRReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SRReLU(l=1/4, u=1/2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SReLU(init_tr: float = 1.0, init_tl: float = 0.0, init_ar: float = 1.0, init_al: float = 0.1, fix_init_epochs: int = 0)[source]
Applies the S-shaped Rectified Linear Unit (SReLU) function:
\(\text{SReLU}(z_i) = \begin{cases} t^r_i + a^r_i(z_i - t^r_i), & z_i \geq t^r_i \\ z_i, & t^r_i > z_i > t^l_i \\ t^l_i + a^l_i(z_i - t^l_i), & z_i \leq t^l_i \end{cases}\)
where \(t^r_i\), \(t^l_i\), \(a^r_i\), and \(a^l_i\) are trainable parameters.
- Parameters:
init_tr (float, optional) – Initial value for the right threshold parameter tr. Default: 1.0
init_tl (float, optional) – Initial value for the left threshold parameter tl. Default: 0.0
init_ar (float, optional) – Initial value for the right slope parameter ar. Default: 1.0
init_al (float, optional) – Initial value for the left slope parameter al. Default: 0.1
fix_init_epochs (int, optional) – Number of epochs to keep parameters fixed at initialization. Default: 0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SReLU(init_tr=1.0, init_tl=0.0, init_ar=1.0, init_al=0.1) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- train(mode=True)[source]
Set the module in training mode.
This has an effect only on certain modules. See the documentation of particular modules for details of their behaviors in training/evaluation mode, i.e., whether they are affected, e.g.
Dropout,BatchNorm, etc.- Parameters:
mode (bool) – whether to set training mode (
True) or evaluation mode (False). Default:True.- Returns:
self
- Return type:
Module
- class torch_activation.SSinH(a_init: float = 1.0, b_init: float = 1.0)[source]
Applies the Scaled Sine-Hyperbolic function:
\(\text{SSinH}(x) = a \cdot \sinh(b \cdot x)\)
where \(a\) and \(b\) are trainable parameters.
- Parameters:
a_init (float, optional) – Initial value for the trainable parameter a. Default: 1.0
b_init (float, optional) – Initial value for the trainable parameter b. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SSinH(a_init=2.0, b_init=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.STACTanh(a: float = 1.0, b: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the Slope and Threshold Adaptive Activation Function with tanh:
- :math:`text{STAC-tanh}(x) = begin{cases}
tanh(-a) + b cdot (x + a), & x < -a \ tanh(x), & -a leq x leq a \ tanh(a) + b cdot (x - a), & x > a
end{cases}`
- Parameters:
a (float, optional) – Threshold parameter. Default: 1.0
b (float, optional) – Slope parameter for linear regions. Default: 0.1
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.STACTanh(a=1.0, b=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.STACTanh(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.STanh(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Scaled Hyperbolic Tangent activation function:
\(\text{STanh}(z) = a \tanh(bz)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.STanh(a=1.7, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.STanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SVAF(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Slope Varying Activation Function:
\(\text{SVAF}(x) = \tanh(a \cdot x)\)
- Parameters:
a (float, optional) – Slope parameter. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SVAF(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SVAF(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ScaledExponentialLinearUnit(a: float = 1.67326, b: float = 1.0)[source]
Applies the Scaled Exponential Linear Unit activation function:
\(\text{ScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.67326
b (float, optional) – Alpha parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ScaledExponentiallyRegularizedLinearUnit(a: float = 1.0, b: float = 1.0)[source]
Applies the Scaled Exponentially Regularized Linear Unit activation function:
\(\text{ScaledExponentiallyRegularizedLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ abz\exp(z), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Regularization parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentiallyRegularizedLinearUnit(a=1.5, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ScaledScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 1.0)[source]
Applies the Scaled Scaled Exponential Linear Unit activation function:
\(\text{ScaledScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(cz) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SechSig[source]
Applies the SechSig activation function:
\(\text{SechSig}(z) = (z + \text{sech}(z))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SechSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SelfArctan[source]
Applies the SelfArctan activation function:
\(\text{SelfArctan}(z) = z \cdot \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SelfArctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Serf[source]
Applies the Serf activation function:
\(\text{Serf}(z) = z \cdot \text{erf}(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Serf() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ShELU(a: float = 1.0, b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Shifted ELU (horizontal) function:
- :math:`text{ShELU}(x) = begin{cases}
x + b, & x + b geq 0 \ a cdot (exp(x + b) - 1), & x + b < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
b (float, optional) – Horizontal shift parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.ShELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ShELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ShHardTanh(a: float = 0.0, inplace: bool = False)[source]
Applies the Shifted HardTanh activation function:
\[\begin{split}\text{ShHardTanh}(z) = \begin{cases} -1, & z < -1 - a, \\ z, & -1 - a \leq z \leq 1 - a, \\ 1, & z > 1 - a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
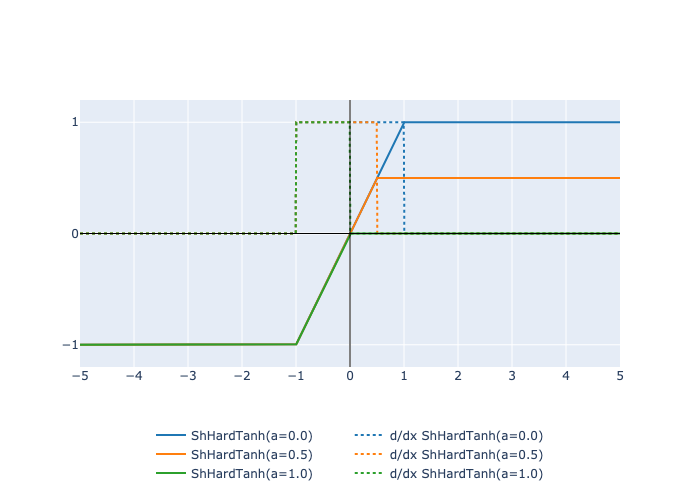
Examples:
>>> m = torch_activation.ShHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ShHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ShiLU(alpha: float = 1.0, beta: float = 0.0, inplace: bool = False)[source]
Applies the ShiLU activation function:
\(\text{ShiLU}(x) = \alpha \cdot \text{ReLU}(x) + \beta\)
- Parameters:
alpha (float, optional) – Scaling factor for the positive part of the input. Default: 1.0.
beta (float, optional) – Bias term added to the output. Default: 0.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.ShiLU(alpha=2.0, beta=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ShiLU(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ShiftedReLU(inplace: bool = False)[source]
A Shifted ReLU is a simple translation of a ReLU and is defined as:
\(\text{ShiftedReLU}(x) = \text{max}(-1, x)\)
See: http://arxiv.org/abs/1511.07289
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
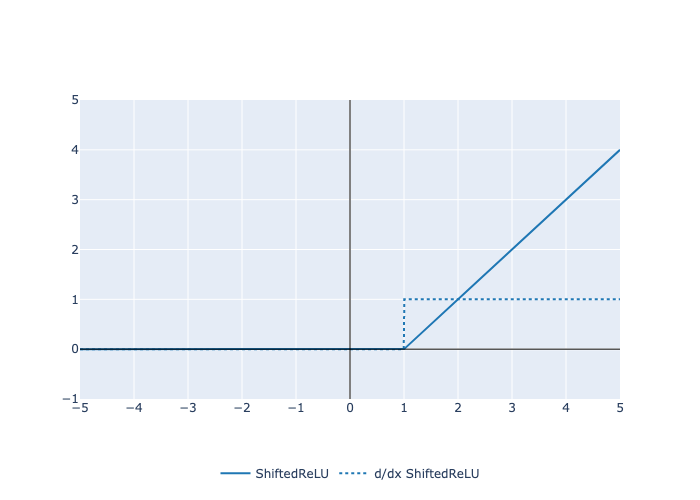
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.ShiftedScaledSigmoid(a: float = 1.0, b: float = 0.0, inplace: bool = False)[source]
Applies the Shifted Scaled Sigmoid activation function:
\(\text{ShiftedScaledSigmoid}(z) = \frac{1}{1 + \exp(-a(z-b))}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Shift parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ShiftedScaledSigmoid(a=2.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ShiftedScaledSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SiELU[source]
Applies the SiELU activation function:
\(\text{SiELU}(z) = z \cdot \sigma\left(\sqrt{\frac{2}{\pi}} z + 0.044715 z^3\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SiELU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SigLin(a: float = 0.2, inplace: bool = False)[source]
Applies the SigLin activation function:
\(\text{SigLin}(z) = \sigma(z) + az\)
- Parameters:
a (float, optional) – Linear coefficient. Default: 0.2
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigLin(a=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigLin(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Sigmoid(inplace: bool = False)[source]
Applies the Sigmoid activation function:
\(\text{Sigmoid}(z) = \frac{1}{1 + \exp(-z)}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Sigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Sigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SigmoidAlgebraic(a: float = 1.0, inplace: bool = False)[source]
Applies the Sigmoid Algebraic activation function:
\(\text{SigmoidAlgebraic}(z) = \frac{1}{1 + \exp\left(-\frac{z(1 + a|z|)}{1 + |z|(1 + a|z|)}\right)}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidAlgebraic(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigmoidAlgebraic(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SigmoidGumbel[source]
Applies the Sigmoid Gumbel activation function:
\(\text{SigmoidGumbel}(z) = \frac{1}{1 + \exp(-z) \exp(-\exp(-z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidGumbel() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SigmoidTanhCombinations(g_func=<built-in method sigmoid of type object>, h_func=<built-in method tanh of type object>)[source]
Applies the Sigmoid-Tanh Combinations activation function:
\(\text{SigmoidTanhCombinations}(z) = \begin{cases} g(z), & z \geq 0 \\ h(z), & z < 0 \end{cases}\)
where g(z) and h(z) are user-defined functions, defaulting to sigmoid and tanh respectively.
- Parameters:
g_func (callable, optional) – Function to use for positive inputs. Default: torch.sigmoid
h_func (callable, optional) – Function to use for negative inputs. Default: torch.tanh
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidTanhCombinations() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom functions >>> import torch.nn.functional as F >>> m = nn.SigmoidTanhCombinations(g_func=F.relu, h_func=torch.sigmoid) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SinLU(a: float = 0.5, b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Sinu-Sigmoidal Linear Unit function:
\(\text{SinLU}(x) = (x + a \cdot \sin(b \cdot x)) \cdot \sigma(x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Amplitude parameter for sine component. Default: 0.5
b (float, optional) – Frequency parameter for sine component. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SinLU(a=0.5, b=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SinLU(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SinSig[source]
Applies the SinSig activation function:
\(\text{SinSig}(z) = z \cdot \sin\left(\frac{\pi}{2} \sigma(z)\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SinSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SincSigmoid[source]
Applies the Sinc Sigmoid activation function:
\(\text{SincSigmoid}(z) = \text{sinc}(\sigma(z))\)
where \(\text{sinc}(x) = \frac{\sin(\pi x)}{\pi x}\) if \(x \neq 0\), and 1 if \(x = 0\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SincSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SineReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\[\begin{split}\text{SineReLU}(z) = \begin{cases} z, & \text{if } z \geq 0 \\ a (\sin(z) - \cos(z)), & \text{if } z < 0 \end{cases}\end{split}\]- Parameters:
a (float, optional) – The scaling parameter for the negative inputs. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
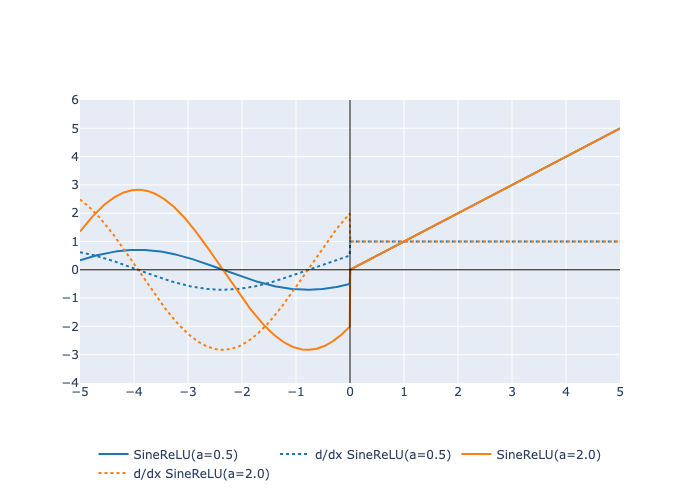
Examples:
>>> m = torch_activation.SineReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SineReLU(a=0.5) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SlReLU(a=10.0, inplace: bool = False)[source]
A Sloped ReLU (SlReLU) [242] is similar to the LReLU — whereas the LReLU parameterizes the slope for negative inputs, the SlReLU parameterizes the slope of ReLU for positive inputs. It is, therefore, defined as:
\[\begin{split}`\text{SlReLU}(z) = \begin{cases} a \cdot z, & z \geq 0, \\ 0, & z < 0, \end{cases}`\end{split}\]a is recommended to be from 1 to 10.
See: https://doi.org/10.1109/pimrc.2017.8292678
- Parameters:
a (float, optional) – The slope for positive inputs. Default: 10.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
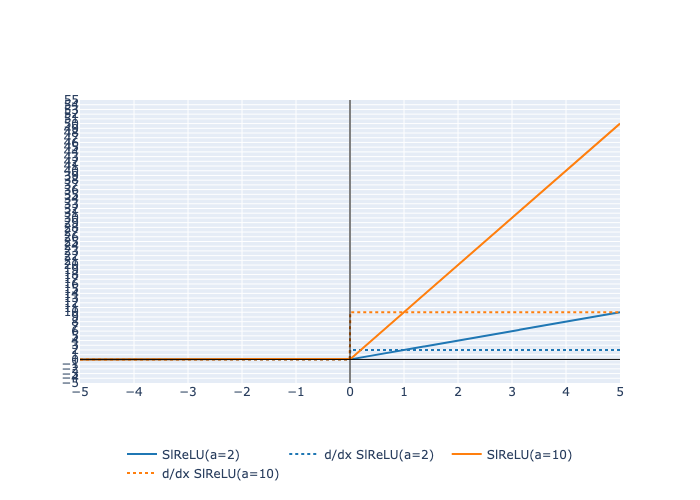
Examples:
>>> m = nn.SlReLU(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SlReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x)[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Smish(a: float = 1.0, b: float = 1.0)[source]
Applies the Smish activation function:
\(\text{Smish}(z) = a \cdot z \cdot \tanh(\ln(1 + \sigma(b \cdot z)))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Smish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SmoothStep(a: float = 2.0, inplace: bool = False)[source]
Applies the Smooth Step activation function:
\(\text{SmoothStep}(z) = \begin{cases} 1, & z \geq \frac{a}{2} \\ \frac{2}{a^3} z^3 - \frac{3}{2a} z + \frac{1}{2}, & -\frac{a}{2} \leq z \leq \frac{a}{2} \\ 0, & z \leq -\frac{a}{2} \end{cases}\)
- Parameters:
a (float, optional) – Width parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SmoothStep(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SmoothStep(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SoftClipping(a: float = 1.0, inplace: bool = False)[source]
Applies the Soft Clipping activation function:
\(\text{SoftClipping}(z) = \frac{1}{a} \ln\left(\frac{1 + \exp(az)}{1 + \exp(a(z-1))}\right)\)
- Parameters:
a (float, optional) – Sharpness parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftClipping(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftClipping(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SoftExponential(a: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Soft Exponential activation function:
- :math:`text{SoftExponential}(x) = begin{cases}
frac{exp(x) - 1}{a} + a, & a > 0 \ x, & a = 0 \ frac{ln(1 - a(x + a))}{-a}, & a < 0
end{cases}`
- Parameters:
a (float, optional) – Shape parameter. Default: 0.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SoftExponential(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SoftExponential(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SoftRootSign(a: float = 2.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Soft Root Sign activation function:
\(\text{SoftRootSign}(z) = \frac{z}{\sqrt[a]{1 + \exp\left(-\frac{z}{b}\right)}}\)
- Parameters:
a (float, optional) – Root parameter. Default: 2.0
b (float, optional) – Scale parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftRootSign(a=3.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftRootSign(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Softshrink(a: float = 0.5, inplace: bool = False)[source]
Applies the Softshrink activation function:
\[\begin{split}\text{Softshrink}(z) = \begin{cases} z - a, & z > a, \\ 0, & -a \leq z \leq a, \\ z + a, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
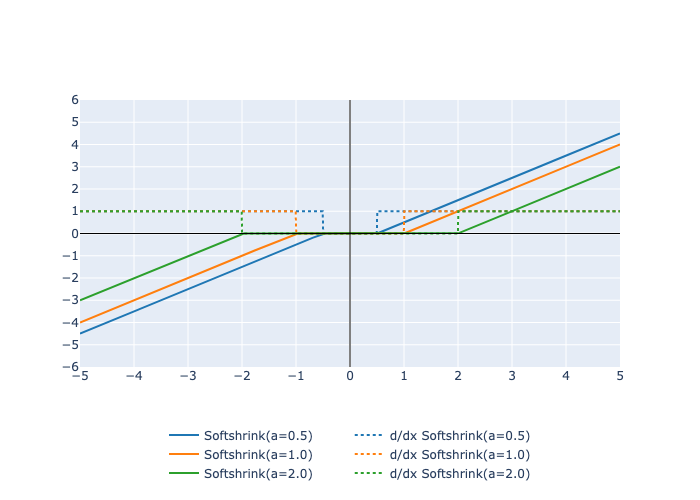
Examples:
>>> m = torch_activation.Softshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Softshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Softsign[source]
Applies the Softsign activation function:
\(\text{Softsign}(z) = \frac{z}{1 + |z|}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Softsign() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SoftsignRReLU(l: float = 0.125, u: float = 0.3333333333333333)[source]
The Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}`\text{S-RReLU}(z_i) = \begin{cases} \frac{1}{(1+z_i)^2} + z_i, & z_i \geq 0, \\ \frac{1}{(1+z_i)^2} + a_i z_i, & z_i < 0, \end{cases}`\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
See: http://dx.doi.org/10.1007/s00521-023-08565-2
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SqREU(inplace: bool = False)[source]
Applies the SqREU (Square Rectified Exponential Unit) activation function:
\(\text{SqREU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqREU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqREU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SqSoftplus(inplace: bool = False)[source]
Applies the SqSoftplus (Square Softplus) activation function:
\(\text{SqSoftplus}(z) = \begin{cases} z, & z > \frac{1}{2} \\ z + \frac{(z + \frac{1}{2})^2}{2}, & -\frac{1}{2} \leq z \leq \frac{1}{2} \\ 0, & z < -\frac{1}{2} \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqSoftplus() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqSoftplus(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SquaredReLU(inplace: bool = False)[source]
Applies the SquaredReLU activation function:
\(\text{SquaredReLU}(z) = \begin{cases} z^2, & z > 0 \\ 0, & z \leq 0 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SquaredReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SquaredReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Squish(inplace: bool = False)[source]
Applies the Squish activation function:
\(\text{Squish}(z) = \begin{cases} z + \frac{z^2}{32}, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Squish() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Squish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.StarReLU(s: float = 0.8944, b: float = -0.4472, learnable: bool = False, inplace: bool = False)[source]
Applies the element-wise function:
\(\text{StarReLU}(x) = s \cdot \text{ReLU}(x)^2 + b\)
- Parameters:
s (float, optional) – Scaled factor for StarReLU, shared across channel. Default: 0.8944
b (float, optional) – Bias term for StarReLU, shared across channel. Default: -0.4472
learnable (bool, optional) – optionally make
sandbtrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.

Examples:
>>> m = torch_activation.StarReLU(s=1.0, b=0.0) >>> x = torch.randn(3, 384, 384) >>> output = m(x) >>> m = torch_activation.StarReLU(learnable=True, inplace=True) >>> x = torch.randn(3, 384, 384) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Suish[source]
Applies the Suish activation function:
\(\text{Suish}(z) = \max(z, z \cdot \exp(-|z|))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Suish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SvELU(a: float = 1.0, b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Shifted ELU (vertical) function:
- :math:`text{SvELU}(x) = begin{cases}
x + b, & x geq 0 \ a cdot (exp(x) - 1) + b, & x < 0
end{cases}`
- Parameters:
a (float, optional) – Scale parameter for negative values. Default: 1.0
b (float, optional) – Vertical shift parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.SvELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SvELU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SvHardTanh(a: float = 0.0, inplace: bool = False)[source]
Applies the Shifted HardTanh activation function:
\[\begin{split}\text{SvHardTanh}(z) = \begin{cases} -1 + a, & z < -1, \\ z + a, & -1 \leq z \leq 1, \\ 1 + a, & z > 1, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
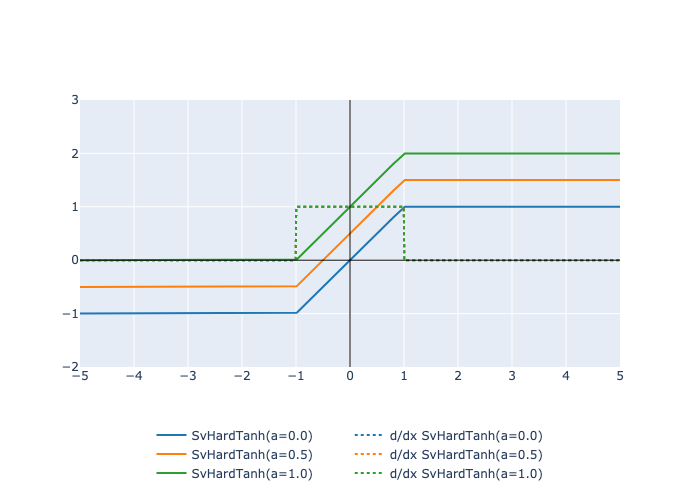
Examples:
>>> m = torch_activation.SvHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SvHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SwAT[source]
Applies the SwAT activation function:
\(\text{SwAT}(z) = z \cdot \frac{1}{1 + \exp(-\arctan(|z|))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SwAT() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Swim(a: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the Swim activation function:
\(\text{Swim}(x) = x \cdot \frac{1}{2} \left(1 + \frac{a \cdot x}{\sqrt{1 + x^2}}\right)\)
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 0.5
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.Swim(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Swim(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Swish(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Swish activation function:
\(\text{Swish}(x) = x \cdot \sigma(a \cdot x)\)
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.Swish(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Swish(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SymmetricalGaussianErrorLinearUnit(a: float = 1.0)[source]
Applies the Symmetrical Gaussian Error Linear Unit activation function:
\(\text{SGELU}(z) = a \cdot z \cdot \text{erf}\left(\frac{z}{\sqrt{2}}\right)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SymmetricalGaussianErrorLinearUnit(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.SymmetricalMSAF(a: float = 1.0)[source]
Applies the Symmetrical Multistate Activation Function:
\(\text{SymmetricalMSAF}(z) = -1 + \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z-a)}\)
- Parameters:
a (float, optional) – Shift parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SymmetricalMSAF(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TBSReLUl(a: float = 0.5, learnable: bool = False, inplace: bool = False)[source]
Applies the Tangent-Bipolar-Sigmoid ReLU Learnable function:
\(\text{TBSReLUl}(x) = x \cdot \tanh\left(a \cdot \frac{1 - \exp(-x)}{1 + \exp(-x)}\right)\)
- Parameters:
a (float, optional) – Parameter controlling the shape of the function. Default: 0.5
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TBSReLUl(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TBSReLUl(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TCA(activation_pool=None, init_a=0.0, init_b=0.0)[source]
Applies the Trainable Compound Activation (TCA) function:
\(\text{TCA}(z_i) = \frac{1}{k} \sum_{j=1}^{k} f_j(\exp(a_{i,j}) z_i + b_{i,j})\)
where \(k\) is the number of mixed functions, and \(a_{i,j}\) and \(b_{i,j}\) are scaling and translation trainable parameters.
- Parameters:
activation_pool (list, optional) – List of activation functions to mix. Default: [nn.Tanh(), nn.ReLU(), nn.SiLU(), nn.Identity()]
init_a (float, optional) – Initial value for the scaling parameters a. Default: 0.0
init_b (float, optional) – Initial value for the translation parameters b. Default: 0.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TCA() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TCAv2(activation_pool=None, init_a=0.0, init_b=0.0, init_c=0.0)[source]
Applies the Trainable Compound Activation Variant 2 (TCAv2) function:
\(\text{TCAv2}(z_i) = \frac{\sum_{j=1}^{k} \exp(a_{i,j}) f_j(\exp(b_{i,j}) z_i + c_{i,j})}{\sum_{j=1}^{k} \exp(a_{i,j})}\)
where \(k\) is the number of mixed functions, and \(a_{i,j}\), \(b_{i,j}\), and \(c_{i,j}\) are scaling and translation trainable parameters.
- Parameters:
activation_pool (list, optional) – List of activation functions to mix. Default: [nn.Tanh(), nn.ReLU(), nn.SiLU(), nn.Identity()]
init_a (float, optional) – Initial value for the vertical scaling parameters a. Default: 0.0
init_b (float, optional) – Initial value for the horizontal scaling parameters b. Default: 0.0
init_c (float, optional) – Initial value for the translation parameters c. Default: 0.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TCAv2() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TReLU(b: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tanh-based ReLU function:
\(\text{TReLU}(x) = \begin{cases} x, & x \geq 0 \\ \tanh(b \cdot x), & x < 0 \end{cases}\)
- Parameters:
b (float, optional) – Scaling factor inside tanh for negative values. Default: 1.0
learnable (bool, optional) – optionally make
btrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TReLU(b=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TReLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TReLU2(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tanh-based ReLU variant 2 function:
\(\text{TReLU2}(x) = \begin{cases} x, & x \geq 0 \\ a \cdot \tanh(x), & x < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scaling factor for tanh component. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TReLU2(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TReLU2(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TRec(a: float = 1.0, inplace: bool = False)[source]
Applies the Truncated Rectified activation function:
\[\begin{split}\text{TRec}(z) = \begin{cases} z, & z > a, \\ 0, & z \leq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
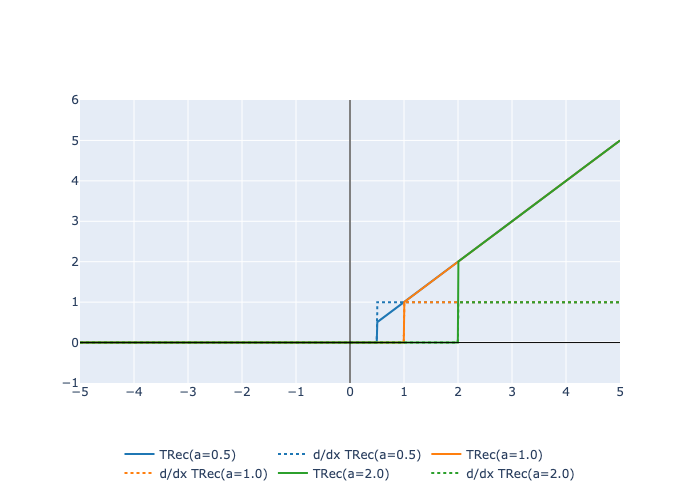
Examples:
>>> m = torch_activation.TRec() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TRec(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TSwish(a: float = 1.0, b: float = 1.0, c: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tunable Swish function:
- :math:`text{T-swish}(x) = begin{cases}
x, & x geq c \ a cdot x cdot sigma(b cdot x), & x < c
end{cases}`
where \(\sigma(x)\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid parameter. Default: 1.0
c (float, optional) – Threshold parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TSwish(a=1.0, b=1.0, c=0.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TSwish(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TaLU(a: float = -1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tangent Linear Unit function:
- :math:`text{TaLU}(x) = begin{cases}
x, & x geq 0 \ tanh(x), & a < x < 0 \ tanh(a), & x leq a
end{cases}`
- Parameters:
a (float, optional) – Lower threshold parameter. Default: -1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TaLU(a=-1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TaLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TangentBipolarSigmoidReLU[source]
Applies the Tangent Bipolar Sigmoid ReLU activation function:
\(\text{TangentBipolarSigmoidReLU}(z) = z \cdot \tanh\left(\frac{1 - \exp(-z)}{1 + \exp(-z)}\right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentBipolarSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TangentSigmoidReLU[source]
Applies the Tangent Sigmoid ReLU activation function:
\(\text{TangentSigmoidReLU}(z) = z \cdot \tanh(\sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Tanh(inplace: bool = False)[source]
Applies the Tanh activation function:
\(\text{Tanh}(z) = \tanh(z)\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Tanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Tanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhExp[source]
Applies the TanhExp activation function:
\(\text{TanhExp}(z) = z \cdot \tanh(\exp(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhExp() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhLU(a: float = 1.0, b: float = 1.0, c: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the TanhLU activation function:
\(\text{TanhLU}(x) = a \cdot \tanh(b \cdot x) + c \cdot x\)
- Parameters:
a (float, optional) – Scaling factor for tanh component. Default: 1.0
b (float, optional) – Scaling factor inside tanh. Default: 1.0
c (float, optional) – Scaling factor for linear component. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TanhLU(a=0.5, b=2.0, c=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TanhLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhLinearUnit[source]
Applies the Tanh Linear Unit activation function:
\(\text{TanhLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{2}{1 + \exp(-z)} - 1, & z < 0 \end{cases} = \begin{cases} z, & z \geq 0 \\ \tanh\left(\frac{z}{2}\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhSig[source]
Applies the TanhSig activation function:
\(\text{TanhSig}(z) = (z + \tanh(z))\sigma(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TanhSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhSoft(a: float = 0.5, b: float = 0.5, c: float = 1.0, d: float = 0.1, learnable: bool = False, inplace: bool = False)[source]
Applies the TanhSoft function:
\(\text{TanhSoft}(x) = \tanh(a \cdot x + b \cdot \exp(c \cdot x)) \cdot \ln(d + \exp(x))\)
where \(a \in (-\infty, 1]\), \(b \in [0, \infty)\), \(c \in (0, \infty)\), \(d \in [0, 1]\).
- Parameters:
a (float, optional) – Parameter for linear term. Default: 0.5
b (float, optional) – Parameter for exponential term. Default: 0.5
c (float, optional) – Parameter for exponential scaling. Default: 1.0
d (float, optional) – Parameter for logarithmic term. Default: 0.1
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TanhSoft(a=0.5, b=0.5, c=1.0, d=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TanhSoft(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhSoft1(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the TanhSoft-1 function:
\(\text{TanhSoft-1}(x) = \tanh(a \cdot x) \cdot \ln(1 + \exp(x))\)
- Parameters:
a (float, optional) – Slope parameter for tanh. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TanhSoft1(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TanhSoft1(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhSoft2(b: float = 1.0, c: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the TanhSoft-2 function:
\(\text{TanhSoft-2}(x) = x \cdot \tanh(b \cdot \exp(c \cdot x))\)
- Parameters:
b (float, optional) – Amplitude parameter. Default: 1.0
c (float, optional) – Exponential scaling parameter. Default: 1.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TanhSoft2(b=1.0, c=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TanhSoft2(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TanhSoft3(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the TanhSoft-3 function:
\(\text{TanhSoft-3}(x) = \ln(1 + \exp(x) \cdot \tanh(a \cdot x))\)
- Parameters:
a (float, optional) – Slope parameter for tanh. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TanhSoft3(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TanhSoft3(learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TeLU(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tanh Exponential Linear Unit function:
\(\text{TeLU}(x) = x \cdot \tanh(\text{ELU}(a \cdot x))\)
where ELU is the Exponential Linear Unit.
- Parameters:
a (float, optional) – Scaling factor inside ELU. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TeLU(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TeLU(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.Tent(a: float = 1.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Tent activation function:
\(\text{Tent}(x) = \max(0, a - |x|)\)
- Parameters:
a (float, optional) – Width parameter of the tent. Default: 1.0
learnable (bool, optional) – optionally make
atrainable. Default:Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.Tent(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Tent(learnable=True, inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TrainableAmplitude(base_activation: ~typing.Callable = <built-in method tanh of type object>, a: float = 1.0, b: float = 0.0, learnable: bool = False, inplace: bool = False)[source]
Applies the Trainable Amplitude function:
\(\text{TrainableAmplitude}(x) = a \cdot g(x) + b\)
where \(g(x)\) is a base activation function.
- Parameters:
base_activation (callable, optional) – Base activation function. Default:
torch.tanha (float, optional) – Amplitude parameter. Default: 1.0
b (float, optional) – Bias parameter. Default: 0.0
learnable (bool, optional) – optionally make parameters trainable. Default:
Falseinplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.TrainableAmplitude(base_activation=torch.tanh, a=1.5, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TrainableAmplitude(base_activation=torch.sigmoid, learnable=True) >>> x = torch.randn(2, 3, 4) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TripleStateSigmoid(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Applies the Triple State Sigmoid activation function:
\(\text{TripleStateSigmoid}(z) = \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)}\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TripleStateSigmoid(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.TripleStateSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.TripleStateSwish(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Applies the Triple State Swish activation function:
\(\text{TSS}(z) = z \cdot \frac{1}{1 + \exp(-z)} \left( \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)} \right)\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TripleStateSwish(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.UnnamedSigmoid1(a: float = 2.0)[source]
- Note:
The name “UnnamesSigmoid1” derived from “3.2.25 Rootsig and others” entry, particularly the first from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 1 activation function:
\(\text{UnnamedSigmoid1}(z) = z \cdot \text{sgn}(z) \sqrt{z^{-a} - a^{-2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 2.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid1(a=3.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.UnnamedSigmoid2(a: float = 1.0)[source]
- Note:
The name “UnnamesSigmoid2” derived from “3.2.25 Rootsig and others” entry, particularly the second from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 2 activation function:
\(\text{UnnamedSigmoid2}(z) = \frac{az}{1 + |az|}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid2(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.UnnamedSigmoid3(a: float = 1.0)[source]
- Note:
The name “UnnamedSigmoid3” derived from “3.2.25 Rootsig and others” entry, particularly the third from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 3 activation function:
\(\text{UnnamedSigmoid3}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid3(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.VLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\(\text{VLU}(x) = \text{ReLU}(x) + a \sin(bx) = \max(0, x) + a \sin(bx)\)
- Parameters:
a (float) – Scaling factor for the sine component. Default:
1.0b (float) – Frequency multiplier for the sine component. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
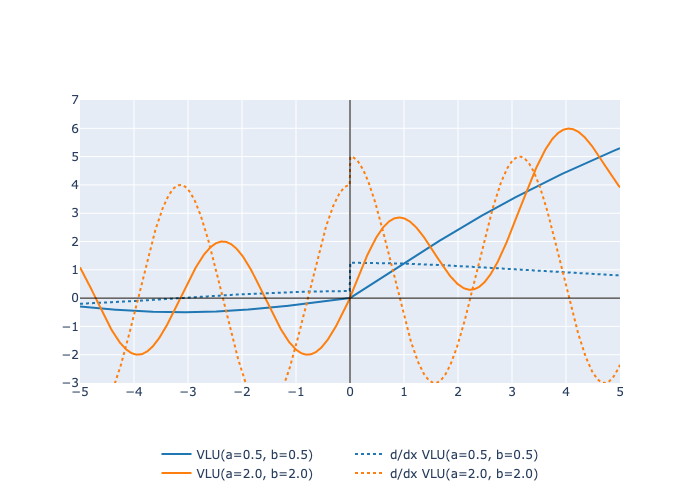
Examples:
>>> m = VLU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.VReLU(inplace: bool = False)[source]
Applies the V-shaped ReLU activation function:
\[\begin{split}\text{vReLU}(z) = |z| = \begin{cases} z, & z \geq 0, \\ -z, & z < 0, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
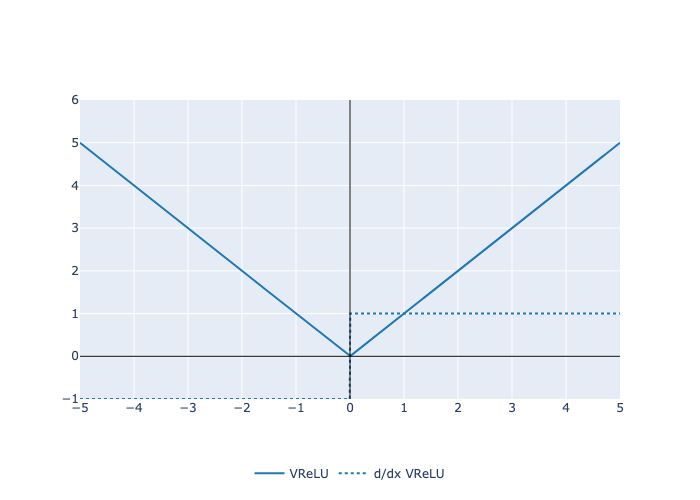
Examples:
>>> m = torch_activation.VReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.VReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.VariantSigmoidFunction(a: float = 1.0, b: float = 1.0, c: float = 0.0, inplace: bool = False)[source]
Applies the Variant Sigmoid Function activation:
\(\text{VariantSigmoidFunction}(z) = \frac{a}{1 + \exp(-bz)} - c\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
c (float, optional) – Offset parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.VariantSigmoidFunction(a=2.0, b=1.5, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.VariantSigmoidFunction(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Classical Activation Functions
- class torch_activation.classical.AbsLU(a: float = 0.5, inplace: bool = False)[source]
Bases:
ModuleApplies the Absolute Linear Unit activation function:
\[\begin{split}\text{AbsLU}(z) = \begin{cases} z, & z \geq 0, \\ a|z|, & z < 0, \end{cases}\end{split}\]where \(a \in [0, 1]\).
- Parameters:
a (float, optional) – Scaling parameter for negative inputs. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.AbsLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AbsLU(a=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Arctan[source]
Bases:
ModuleApplies the Arctan activation function:
\(\text{Arctan}(z) = \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Arctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ArctanGR[source]
Bases:
ModuleApplies the ArctanGR activation function:
\(\text{ArctanGR}(z) = \frac{\arctan(z)}{1 + \sqrt{2}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ArctanGR() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ArctanSiLU[source]
Bases:
ModuleApplies the Arctan SiLU activation function:
\(\text{ArctanSiLU}(z) = \arctan(z) \cdot \frac{1}{1 + \exp(-z)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ArctanSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.BLReLU(a: float = 0.1, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Bounded Leaky ReLU activation function:
\[\begin{split}\text{BLReLU}(z) = \begin{cases} az, & z \leq 0, \\ z, & 0 < z < b, \\ az + c, & z \geq b, \end{cases}\end{split}\]where \(c = (1 - a)b\).
- Parameters:
a (float, optional) – Slope parameter for negative and large positive inputs. Default:
0.1b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.BLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BLReLU(a=0.2, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.BReLU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Bounded ReLU activation function:
\[\begin{split}\text{BReLU}(z) = \min(\max(0, z), a) = \begin{cases} 0, & z \leq 0, \\ z, & 0 < z < a, \\ a, & z \geq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Upper bound for the function’s output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.BReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BReLU(a=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Binary(inplace: bool = False)[source]
Bases:
ModuleApplies the Binary activation function:
\(\text{Binary}(z) = \begin{cases} 0, & z < 0 \\ 1, & z \geq 0 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.CCAF(a: float = 0.5, b: float = 0.5, iterations: int = 1)[source]
Bases:
ModuleApplies the Cascade Chaotic Activation Function:
\[f(z_{i+1}) = a \cdot \sin(\pi \cdot b \cdot \sin(\pi z_i))\]where \(a, b \in [0, 1]\).
- Parameters:
a (float, optional) – Amplitude parameter. Default:
0.5b (float, optional) – Inner sine scaling parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.CCAF() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.CCAF(a=0.8, b=0.7, iterations=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.CReLU(dim: int = 0)[source]
Bases:
ModuleApplies the Concatenated Rectified Linear Unit activation function.
\(\text{CReLU}(x) = \text{ReLU}(x) \oplus \text{ReLU}(-x)\)
- Parameters:
dim (int, optional) – Dimension along which to concatenate in the output tensor. Default: 1
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.CReLU() >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = torch_activation.CReLU(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.CauchyLinearUnit[source]
Bases:
ModuleApplies the Cauchy Linear Unit activation function:
\(\text{CaLU}(z) = z \cdot \Phi_{\text{Cauchy}}(z) = z \cdot \left( \frac{\arctan(z)}{\pi} + \frac{1}{2} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CauchyLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.CoLU(inplace=False)[source]
Bases:
ModuleApplies the Collapsing Linear Unit activation function:
\(\text{CoLU}(x) = \frac{x}{1-x \cdot e^{-(x + e^x)}}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.CoLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.CoLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.CollapsingLinearUnit(inplace=False)[source]
Bases:
ModuleApplies the Collapsing Linear Unit activation function:
\(\text{CoLU}(z) = z \cdot \frac{1}{1 - z \exp(-(z + \exp(z)))}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CollapsingLinearUnit() >>> x = torch.randn(2) >>> output = m(x) >>> m = CollapsingLinearUnit(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ComplementaryLogLog[source]
Bases:
ModuleApplies the Complementary LogLog activation function:
\(\text{ComplementaryLogLog}(z) = 1 - \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.DerivativeOfSiLU[source]
Bases:
ModuleApplies the Derivative of SiLU activation function:
\(\text{DerivativeOfSiLU}(z) = \sigma(z) \cdot (1 + z \cdot (1 - \sigma(z)))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.DerivativeOfSigmoidFunction[source]
Bases:
ModuleApplies the Derivative of Sigmoid Function activation:
\(\text{DerivativeOfSigmoidFunction}(z) = \exp(-z) \cdot (\sigma(z))^2\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSigmoidFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.DifferenceELU(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the Difference ELU activation function:
\(\text{DifferenceELU}(z) = \begin{cases} z, & z \geq 0 \\ a(z\exp(z) - b\exp(bz)), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DifferenceELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.DoubleSiLU[source]
Bases:
ModuleApplies the Double SiLU activation function:
\(\text{DoubleSiLU}(z) = z \cdot \frac{1}{1 + \exp\left(-z \cdot \frac{1}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DoubleSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.DualELU(alpha: float = 1.0, dim: int = -1)[source]
Bases:
ModuleApplies the Dual ELU activation function:
\(\text{DualELU}(z, z') = \text{ELU}(z) - \text{ELU}(z')\)
- Parameters:
alpha (float, optional) – The alpha value for the ELU formulation. Default: 1.0
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = DualELU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.EfficientAsymmetricNonlinearActivationFunction[source]
Bases:
ModuleApplies the Efficient Asymmetric Nonlinear Activation Function:
\(\text{EfficientAsymmetricNonlinearActivationFunction}(z) = z \cdot \frac{\exp(z)}{\exp(z) + 2}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = EfficientAsymmetricNonlinearActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ElasticAdaptivelyParametricCompoundedUnit(a: float = 1.0, b: float = 1.0, num_parameters: int = 1)[source]
Bases:
ModuleApplies the Elastic Adaptively Parametric Compounded Unit activation function:
\(\text{ElasticAdaptivelyParametricCompoundedUnit}(z_i) = \begin{cases} b_i z_i, & z_i \geq 0 \\ a_i z_i \cdot \tanh(\ln(1 + \exp(a_{i}z_{i}))), & z_i < 0 \end{cases}\)
- Parameters:
a (float or Tensor, optional) – Negative slope parameter. Default: 1.0
b (float or Tensor, optional) – Positive slope parameter. Default: 1.0
num_parameters (int, optional) – Number of parameters if using per-channel parameterization. Default: 1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ElasticAdaptivelyParametricCompoundedUnit(a=0.5, b=1.5) >>> x = torch.randn(2) >>> output = m(x) >>> # Per-channel parameterization >>> m = ElasticAdaptivelyParametricCompoundedUnit(num_parameters=3) >>> x = torch.randn(3, 5) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ElliottActivationFunction[source]
Bases:
ModuleApplies the Elliott Activation Function:
\(\text{ElliottActivationFunction}(z) = \frac{0.5z}{1 + |z|} + 0.5\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ElliottActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ExpExpish[source]
Bases:
ModuleApplies the ExpExpish activation function:
\(\text{ExpExpish}(z) = z \cdot \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExpExpish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ExponentialLinearSigmoidSquashing[source]
Bases:
ModuleApplies the Exponential Linear Sigmoid Squashing activation function:
\(\text{ExponentialLinearSigmoidSquashing}(z) = \begin{cases} \frac{z}{1 + \exp(-z)}, & z \geq 0 \\ \frac{\exp(z) - 1}{1 + \exp(-z)}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ExponentialSwish[source]
Bases:
ModuleApplies the Exponential Swish activation function:
\(\text{ExponentialSwish}(z) = \exp(-z) \cdot \sigma(z)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.FCAF_Hidden(r: float = 4.0, a: float = 0.0, b: float = 0.5, iterations: int = 1)[source]
Bases:
ModuleApplies the Fusion of Chaotic Activation Function for hidden units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i)\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Hidden() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Hidden(r=3.9, a=0.1, b=0.3, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.FCAF_Output(r: float = 4.0, a: float = 0.0, b: float = 0.5, c: float = 1.0, d: float = 0.0, iterations: int = 1)[source]
Bases:
ModuleApplies the Fusion of Chaotic Activation Function for output units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i) + \exp(-cz_i^2) + d\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5c (float, optional) – Gaussian width parameter. Default:
1.0d (float, optional) – Constant shift parameter. Default:
0.0iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Output() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Output(r=3.9, a=0.1, b=0.3, c=2.0, d=0.1, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.FasterPowerFunctionLinearUnit[source]
Bases:
ModuleApplies the Faster Power Function Linear Unit activation function:
\(\text{FasterPowerFunctionLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ z + \frac{z^2}{\sqrt{1 + z^2}}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = FasterPowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GEGLU(dim: int = -1)[source]
Bases:
ModuleApplies the Gated GELU function:
\(\text{GatedGELU}(z, z') = z \otimes \text{GELU}(z')\)
where \(\otimes\) is element-wise multiplication.
- Parameters:
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = GEGLU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GLU(dim: int = -1)[source]
Bases:
ModuleApplies the Gated Linear Unit function:
\(\text{GLU}(z, z') = z \otimes \sigma(z')\)
where \(\sigma\) is the sigmoid function and \(\otimes\) is element-wise multiplication.
- Parameters:
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = GLU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GReLU(dim: int = -1)[source]
Bases:
ModuleApplies the Gated ReLU function:
\(\text{GatedReLU}(z, z') = z \otimes \text{ReLU}(z')\)
where \(\otimes\) is element-wise multiplication.
- Parameters:
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = GReLU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GTU(dim: int = -1)[source]
Bases:
ModuleApplies the Gated Tanh Unit function:
\(\text{GTU}(z, z') = \tanh(z) \otimes \sigma(z')\)
where \(\sigma\) is the sigmoid function and \(\otimes\) is element-wise multiplication.
- Parameters:
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = GTU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GaussianErrorLinearUnit[source]
Bases:
ModuleApplies the Gaussian Error Linear Unit activation function:
\(\text{GELU}(z) = z \cdot \Phi(z) = z \cdot \frac{1}{2} \left( 1 + \text{erf}\left(\frac{z}{\sqrt{2}}\right) \right)\)
This is a wrapper around PyTorch’s native F.gelu implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GaussianErrorLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.GeneralizedSwish[source]
Bases:
ModuleApplies the Generalized Swish activation function:
\(\text{GSwish}(z) = z \cdot \sigma(\exp(-z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GeneralizedSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Gish[source]
Bases:
ModuleApplies the Gish activation function:
\(\text{Gish}(z) = z \cdot \ln(2 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Gish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HCAF(r: float = 4.0, iterations: int = 3)[source]
Bases:
ModuleApplies the Hybrid Chaotic Activation Function:
\[ \begin{align}\begin{aligned}a_i = \sigma(z_i)\\c_{i,1} = ra_i(1 - a_i)\\c_{i,j} = rc_{i,j-1}(1 - c_{i,j-1})\end{aligned}\end{align} \]where \(\sigma(z_i)\) is the logistic sigmoid and \(r = 4\) by default.
- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0iterations (int, optional) – Number of iterations for the chaotic map. Default:
3
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.HCAF() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HCAF(r=3.9, iterations=5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HardExponentialLinearSigmoidSquashing[source]
Bases:
ModuleApplies the Hard Exponential Linear Sigmoid Squashing activation function:
\(\text{HardExponentialLinearSigmoidSquashing}(z) = \begin{cases} z \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z \geq 0 \\ (1 + \exp(-z)) \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HardSReLUE(a: float = 1.0)[source]
Bases:
ModuleApplies the Hard SReLUE activation function:
\(\text{HardSReLUE}(z) = \begin{cases} az \cdot \max\left(0, \min\left(1, \frac{z+1}{2} + z\right)\right), & z \geq 0 \\ a(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardSReLUE(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HardSigmoid(version: str = 'v1', inplace: bool = False)[source]
Bases:
ModuleApplies the Hard Sigmoid activation function:
\(\text{HardSigmoid}(z) = \max(0, \min(\frac{z+1}{2}, 1))\)
or alternatively:
\(\text{HardSigmoid}(z) = \max(0, \min(0.2z + 0.5, 1))\)
- Parameters:
version (str, optional) – Version of hard sigmoid to use (‘v1’ or ‘v2’). Default:
'v1'inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.HardSigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSigmoid(version='v2', inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HardSwish(inplace: bool = False)[source]
Bases:
ModuleApplies the Hard Swish activation function:
\[\begin{split}\text{Hard swish}(z) = z \cdot \begin{cases} 0, & z \leq -3, \\ 1, & z \geq 3, \\ \frac{z}{6} + \frac{1}{2}, & -3 < z < 3, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.HardSwish() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSwish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HardTanh(a: float = -1.0, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the HardTanh activation function:
\[\begin{split}\text{HardTanh}(z) = \begin{cases} a, & z < a, \\ z, & a \leq z \leq b, \\ b, & z > b, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Lower bound of the linear region. Default:
-1.0b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.HardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardTanh(a=-2.0, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Hardshrink(a: float = 0.5, inplace: bool = False)[source]
Bases:
ModuleApplies the Hardshrink activation function:
\[\begin{split}\text{Hardshrink}(z) = \begin{cases} z, & z > a, \\ 0, & -a \leq z \leq a, \\ z, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.Hardshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Hardshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Hexpo(a: float = 1.0, b: float = 1.0, c: float = 1.0, d: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Hexpo activation function:
\(\text{Hexpo}(z) = \begin{cases} -a \exp\left(-\frac{z}{b}\right) - 1, & z \geq 0 \\ c \exp\left(-\frac{z}{d}\right) - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Positive scale parameter. Default: 1.0
b (float, optional) – Positive decay parameter. Default: 1.0
c (float, optional) – Negative scale parameter. Default: 1.0
d (float, optional) – Negative decay parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Hexpo(a=1.5, b=0.5, c=2.0, d=0.7) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Hexpo(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.HyperbolicTangentSiLU[source]
Bases:
ModuleApplies the Hyperbolic Tangent SiLU activation function:
\(\text{HyperbolicTangentSiLU}(z) = \frac{\exp\left(\frac{z}{1 + \exp(-z)}\right) - \exp\left(-\frac{z}{1 + \exp(-z)}\right)}{\exp\left(\frac{z}{1 + \exp(-z)}\right) + \exp\left(\frac{z}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HyperbolicTangentSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ISRLU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the ISRLU (Inverse Square Root Linear Unit) activation function:
\(\text{ISRLU}(z) = \begin{cases} z, & z \geq 0 \\ \frac{z}{\sqrt{1 + az^2}}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ISRU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the ISRU (Inverse Square Root Unit) activation function:
\(\text{ISRU}(z) = \frac{z}{\sqrt{1 + az^2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ImprovedLogisticSigmoid(a: float = 0.2, b: float = 2.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Improved Logistic Sigmoid activation function:
\(\text{ImprovedLogisticSigmoid}(z) = \begin{cases} a(z-b) + \sigma(b), & z \geq b \\ \sigma(z), & -b < z < b \\ a(z+b) + \sigma(-b), & z \leq -b \end{cases}\)
- Parameters:
a (float, optional) – Slope parameter. Default: 0.2
b (float, optional) – Threshold parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ImprovedLogisticSigmoid(a=0.1, b=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ImprovedLogisticSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.InversePolynomialLinearUnit(a: float = 1.0)[source]
Bases:
ModuleApplies the Inverse Polynomial Linear Unit activation function:
\(\text{InversePolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 + |z|^a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = InversePolynomialLinearUnit(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LReLU(a: float = 100.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Leaky ReLU activation function.
\[\begin{split}\text{LReLU}(z) = \begin{cases} z, & z \geq 0, \\ \frac{z}{a}, & z < 0, \end{cases}\end{split}\]where \(a\) is recommended to be 100.
- Parameters:
a (float, optional) – The denominator for negative inputs. Default:
100.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.LReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LReLU(a=50.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LSPTLU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Linear Symmetric Piecewise Triangular Linear Unit activation function:
\[\begin{split}\text{LSPTLU}(z) = \begin{cases} 0.2z, & z < 0, \\ z, & 0 \leq z \leq a, \\ 2a - z, & a < z \leq 2a, \\ 0, & z > 2a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the shape. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.LSPTLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LSPTLU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LSReLU(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the LSReLU activation function:
\(\text{LSReLU}(z) = \begin{cases} \frac{z}{1 + |z|}, & z \leq 0 \\ z, & 0 \leq z \leq b \\ \log(az + 1) + |\log(ab + 1) - b|, & z \geq b \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > b. Default: 1.0
b (float, optional) – Threshold parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LSReLU(a=0.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LaplaceLinearUnit[source]
Bases:
ModuleApplies the Laplace Linear Unit activation function:
\(\text{LaLU}(z) = z \cdot \Phi_{\text{Laplace}}(z) = z \cdot \begin{cases} 1 - \frac{1}{2} \exp(-z), & z \geq 0 \\ \frac{1}{2} \exp(z), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LaplaceLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LeakyScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 0.1)[source]
Bases:
ModuleApplies the Leaky Scaled Exponential Linear Unit activation function:
\(\text{LeakyScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1) + acz, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Leaky slope. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LeakyScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LinComb(activations: Iterable[Module] = [ReLU(), Sigmoid(), Tanh(), Softsign()])[source]
Bases:
ModuleApplies the LinComb activation function:
\(\text{LinComb}(x) = \sum_{i=1}^{n} w_i \cdot F_i(x)\)
- Parameters:
activations (Iterable[nn.Module]) – List of activation functions. Default: [nn.ReLU, nn.Sigmoid, nn.Tanh, nn.Softsign]
- Shape:
Input: \((*)\) where \(*\) means any number of additional dimensions.
Output: \((*)\)
Here is a plot of the function and its derivative:

Examples:
>>> activations = [nn.ReLU(), nn.Sigmoid()] >>> m = LinComb(activation_functions) >>> input = torch.randn(10) >>> output = m(input)
- forward(input) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LinQ(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the LinQ (Linear Quadratic) activation function:
\(\text{LinQ}(z) = \begin{cases} az + 1 - 2z + z^2, & z \geq 2 - 2a \\ \frac{1}{4}z(4 - |z|), & -2 + 2a < z < 2 - 2a \\ az - 1 - 2z + z^2, & z \leq -2 + 2a \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LinQ(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LinQ(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LinearlyScaledHyperbolicTangent[source]
Bases:
ModuleApplies the Linearly Scaled Hyperbolic Tangent activation function:
\(\text{LinearlyScaledHyperbolicTangent}(z) = z \cdot \tanh(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LinearlyScaledHyperbolicTangent() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LipschitzReLU(p_fn=None, n_fn=None)[source]
Bases:
ModuleApplies the Lipschitz ReLU activation function:
\(\text{LipschitzReLU}(z) = p(z | z > 0) + n(z | z \leq 0)\)
where p and n are positive and negative functions with Lipschitz constant <= 1.
- Parameters:
p_fn (callable, optional) – Positive function. Default: identity
n_fn (callable, optional) – Negative function. Default: zero
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> # Default implementation (standard ReLU) >>> m = LipschitzReLU() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom implementation with leaky behavior >>> m = LipschitzReLU(p_fn=lambda x: x, n_fn=lambda x: 0.1 * x) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LogLog[source]
Bases:
ModuleApplies the LogLog activation function:
\(\text{LogLog}(z) = \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LogLogish[source]
Bases:
ModuleApplies the LogLogish activation function:
\(\text{LogLogish}(z) = z \cdot (1 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogLogish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LogSQNL(inplace: bool = False)[source]
Bases:
ModuleApplies the LogSQNL (Logarithmic Square Non-Linear) activation function:
\(\text{LogSQNL}(z) = \begin{cases} 1, & z > 2 \\ \frac{1}{2}z - \frac{z^2}{4} + \frac{1}{2}, & 0 \leq z \leq 2 \\ \frac{1}{2}z + \frac{z^2}{4} + \frac{1}{2}, & -2 \leq z < 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogSQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LogSQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.LogSigmoid[source]
Bases:
ModuleApplies the LogSigmoid activation function:
\(\text{LogSigmoid}(z) = \ln(\sigma(z)) = \ln\left(\frac{1}{1 + \exp(-z)}\right)\)
This is a wrapper around PyTorch’s native F.logsigmoid implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Logish[source]
Bases:
ModuleApplies the Logish activation function:
\(\text{Logish}(z) = z \cdot \ln(1 + \sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Logish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.MEF(inplace: bool = False)[source]
Bases:
ModuleApplies the MEF (Modified Error Function) activation function:
\(\text{MEF}(z) = \frac{z}{\sqrt{1 + z^2} + 2}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MEF() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.MEF(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.MReLU(inplace: bool = False)[source]
Bases:
ModuleApplies the Mirrored Rectified Linear Unit activation function:
\[\begin{split}\text{mReLU}(z) = \min(\text{ReLU}(1 - z), \text{ReLU}(1 + z)) = \begin{cases} 1 + z, & -1 \leq z \leq 0, \\ 1 - z, & 0 < z \leq 1, \\ 0, & \text{otherwise}, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.MReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.MReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Minsin(inplace: bool = False)[source]
Bases:
ModuleApplies the element-wise function:
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = Minsin() >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Mish[source]
Bases:
ModuleApplies the Mish activation function:
\(\text{Mish}(z) = z \cdot \tanh(\text{softplus}(z)) = z \cdot \tanh(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Mish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ModifiedComplementaryLogLog[source]
Bases:
ModuleApplies the Modified Complementary LogLog activation function:
\(\text{ModifiedComplementaryLogLog}(z) = 1 - 2\exp(-0.7\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ModifiedComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ModifiedSiLU[source]
Bases:
ModuleApplies the Modified SiLU activation function:
\(\text{ModifiedSiLU}(z) = z \cdot \sigma(z) + \exp\left(-\frac{z^2}{4}\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ModifiedSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.MultistateActivationFunction(a: float = 0.0, b: list = None)[source]
Bases:
ModuleApplies the Multistate Activation Function:
\(\text{MultistateActivationFunction}(z) = a + \sum_{k=1}^N \frac{1}{1 + \exp(-z+b_k)}\)
- Parameters:
a (float, optional) – Offset parameter. Default: 0.0
b (list of float, optional) – List of shift parameters. Default: [1.0, 2.0]
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MultistateActivationFunction(a=0.5, b=[0.5, 1.5, 2.5]) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.NLReLU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Natural-Logarithm-ReLU activation function:
\(\text{NLReLU}(z) = \ln(a \cdot \max(0, z) + 1)\)
- Parameters:
a (float, optional) – Scaling factor for the ReLU output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.NLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NLReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.NReLU(sigma: float = 0.1, inplace: bool = False)[source]
Bases:
ModuleApplies the Noisy ReLU activation function.
\[\text{NReLU}(z) = \max(0, z + a)\]where \(a \sim N(0, \sigma(z))\) is sampled from a Gaussian distribution.
- Parameters:
sigma (float, optional) – Standard deviation for the noise. Default:
0.1inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.NReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NReLU(sigma=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.NewSigmoid[source]
Bases:
ModuleApplies the New Sigmoid activation function:
\(\text{NewSigmoid}(z) = \frac{\exp(z) - \exp(-z)}{2(\exp(2z) + \exp(-2z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.NewSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.NormLinComb(activations: Iterable[Module] = [ReLU(), Sigmoid(), Tanh(), Softsign()])[source]
Bases:
ModuleApplies the LinComb activation function:
\(\text{NormLinComb}(x) = \frac{\sum_{i=1}^{n} w_i \cdot F_i(x)}{\|\|W\|\|}\)
- Parameters:
activations (Iterable[nn.Module]) – List of activation functions. Default: [nn.ReLU, nn.Sigmoid, nn.Tanh, nn.Softsign]
- Shape:
Input: \((*)\) where \(*\) means any number of additional dimensions.
Output: \((*)\)
Here is a plot of the function and its derivative:

Examples:
>>> activations = [nn.ReLU, nn.Sigmoid] >>> m = NormLinComb(activation_functions) >>> input = torch.randn(10) >>> output = m(input)
- forward(input) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.OLReLU(l: float = 3.0, u: float = 8.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Optimized Leaky ReLU activation function.
\[\begin{split}\text{OLReLU}(z) = \begin{cases} z, & z \geq 0, \\ z \cdot \exp(-a), & z < 0, \end{cases}\end{split}\]where \(a = \frac{u+l}{u-l}\).
- Parameters:
l (float, optional) – Lower bound parameter. Default:
3.0u (float, optional) – Upper bound parameter. Default:
8.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.OLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.OLReLU(l=2.0, u=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PReNU(a: float = 0.25, inplace: bool = False)[source]
Bases:
ModuleApplies the Parametric Rectified Non-linear Unit activation function:
\[\begin{split}\text{PReNU}(z) = \begin{cases} z - a \ln(z + 1), & z \geq 0, \\ 0, & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the logarithmic term. Default:
0.25inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.PReNU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PReNU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PanFunction(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Pan activation function:
\[\begin{split}\text{Pan function}(z) = \begin{cases} z - a, & z \geq a, \\ 0, & -a < z < a, \\ -z - a, & z \leq -a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.PanFunction() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PanFunction(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ParametricLogish(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the Parametric Logish activation function:
\(\text{ParametricLogish}(z_i) = a \cdot z_i \cdot \ln(1 + \sigma(b \cdot z_i))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ParametricLogish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ParametricSechSig(a: float = 1.0)[source]
Bases:
ModuleApplies the Parametric SechSig activation function:
\(\text{ParametricSechSig}(z) = (z + a\cdot \text{sech}(z+a))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricSechSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ParametricTanhSig(a: float = 1.0)[source]
Bases:
ModuleApplies the Parametric TanhSig activation function:
\(\text{ParametricTanhSig}(z) = (z + a\cdot \tanh(z+a))\sigma(z)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricTanhSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PenalizedHyperbolicTangent(a: float = 2.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Penalized Hyperbolic Tangent activation function:
\(\text{PenalizedHyperbolicTangent}(z) = \begin{cases} \tanh(z), & z \geq 0 \\ \frac{\tanh(z)}{a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Penalty factor for negative inputs. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.PenalizedHyperbolicTangent(a=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.PenalizedHyperbolicTangent(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Phish[source]
Bases:
ModuleApplies the Phish activation function:
\(\text{Phish}(z) = z \cdot \tanh(\text{GELU}(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Phish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PolynomialLinearUnit[source]
Bases:
ModuleApplies the Polynomial Linear Unit activation function:
\(\text{PolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 - z} - 1, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PolynomialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PowerFunctionLinearUnit[source]
Bases:
ModuleApplies the Power Function Linear Unit activation function:
\(\text{PowerFunctionLinearUnit}(z) = z \cdot \frac{1}{2} \left( 1 + \frac{z}{\sqrt{1 + z^2}} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.PowerLinearUnit(a: float = 1.0)[source]
Bases:
ModuleApplies the Power Linear Unit activation function:
\(\text{PowerLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ (1 - z)^{-a} - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerLinearUnit(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.RReLU(l: float = 3.0, u: float = 8.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Randomized Leaky ReLU activation function.
\[\begin{split}\text{RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ z_i a_i, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled from a uniform distribution \(U(l, u)\), with recommended values \(U(3, 8)\).
- Parameters:
l (float, optional) – Lower bound of the uniform distribution. Default:
3.0u (float, optional) – Upper bound of the uniform distribution. Default:
8.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.RReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RReLU(l=2.0, u=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.RSigELU(a: float = 1.0)[source]
Bases:
ModuleApplies the RSigELU activation function:
\(\text{RSigELU}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \geq z \geq 1 \\ a(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELU(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.RSigELUD(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the RSigELUD activation function:
\(\text{RSigELUD}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \leq z \leq 1 \\ b(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > 1. Default: 1.0
b (float, optional) – Scale parameter for z < 0. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELUD(a=1.5, b=0.8) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.RTReLU(sigma: float = 0.75, inplace: bool = False)[source]
Bases:
ModuleApplies the Randomly Translational ReLU activation function:
\[\begin{split}\text{RT-ReLU}(z_i) = \begin{cases} z_i + a_i, & z_i + a_i \geq 0, \\ 0, & z_i + a_i < 0, \end{cases}\end{split}\]where \(a_i \sim N(0, \sigma^2)\) is sampled from a Gaussian distribution.
- Parameters:
sigma (float, optional) – Standard deviation for the Gaussian noise. Default:
0.75inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.RTReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RTReLU(sigma=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ReLUN(n: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the element-wise function:
\(\text{ReLUN}(x) = \min(\text{ReLU}(x), n)\)
- Parameters:
n (float, optional) – Upper bound for the function’s output. Default is 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ReLUN(n=6.0) # ReLU6 >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReLUN(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ReSP(a: float = 1.7, inplace: bool = False)[source]
Bases:
ModuleApplies the Rectified Softplus activation function:
\[\begin{split}\text{ReSP}(z) = \begin{cases} az + \ln(2), & z \geq 0, \\ \ln(1 + \exp(z)), & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Scaling factor for positive inputs. Default:
1.7inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ReSP() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReSP(a=1.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.RectifiedHyperbolicSecant[source]
Bases:
ModuleApplies the Rectified Hyperbolic Secant activation function:
\(\text{RectifiedHyperbolicSecant}(z) = z \cdot \text{sech}(z)\)
where sech is the hyperbolic secant function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RectifiedHyperbolicSecant() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Root2sigmoid[source]
Bases:
ModuleApplies the Root2sigmoid activation function:
\(\text{Root2sigmoid}(z) = \frac{\sqrt{2}z}{\sqrt{2^{-2z}} + \sqrt{2^{2z}}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Root2sigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Rootsig(a: float = 1.0)[source]
Bases:
ModuleApplies the Rootsig activation function:
\(\text{Rootsig}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Rootsig(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SCAA(channels: int, kernel_size: int = 3, padding: int = 1)[source]
Bases:
ModuleApplies the Spatial Context-Aware Activation function:
\(\text{SCAA}(X) = \max(X, f_{DW}(X))\)
where \(f_{DW}\) is a depthwise convolution operation.
- Parameters:
channels (int) – Number of input channels
kernel_size (int, optional) – Size of the convolving kernel. Default:
3padding (int, optional) – Padding added to all sides of the input. Default:
1
- Shape:
Input: \((N, C, H, W)\) or \((C, H, W)\)
Output: Same shape as the input
Examples:
>>> m = torch_activation.SCAA(channels=64) >>> x = torch.randn(1, 64, 28, 28) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SLU(inplace: bool = False)[source]
Bases:
ModuleApplies the Softplus Linear Unit activation function:
\[\begin{split}\text{SLU}(z) = \begin{cases} az, & z \geq 0, \\ b \ln(\exp(z) + 1) - c, & z < 0, \end{cases}\end{split}\]which simplifies to:
\[\begin{split}\text{SLU}(z) = \begin{cases} z, & z \geq 0, \\ 2 \ln(\frac{\exp(z) + 1}{2}), & z < 0, \end{cases}\end{split}\]where \(a=1, b=2, c=2\ln(2)\).
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.SLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SQLU(inplace: bool = False)[source]
Bases:
ModuleApplies the SQLU (Square Linear Unit) activation function:
\(\text{SQLU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{4}, & -2 \leq z \leq 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SQMAX(c: float = 0.0, dim: int = -1)[source]
Bases:
ModuleApplies the SQMAX (Square Maximum) activation function:
\(\text{SQMAX}(z_j) = \frac{(z_j + c)^2}{\sum_{k=1}^N (z_k + c)^2}\)
- Parameters:
c (float, optional) – Offset parameter. Default: 0.0
dim (int, optional) – A dimension along which SQMAX will be computed. Default: -1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQMAX(c=1.0) >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = nn.SQMAX(dim=0) >>> x = torch.randn(2, 3) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SQNL(inplace: bool = False)[source]
Bases:
ModuleApplies the SQNL (Square Non-Linear) activation function:
\(\text{SQNL}(z) = \begin{cases} 1, & z > 2 \\ z - \frac{z^2}{4}, & 0 \leq z \leq 2 \\ z + \frac{z^2}{4}, & -2 \leq z < 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SRReLU(l: float = 0.125, u: float = 0.3333333333333333, inplace: bool = False)[source]
Bases:
ModuleThe Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}\text{S-RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ \frac{z_i}{a_i}, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.SRReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SRReLU(l=1/4, u=1/2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.STanh(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Scaled Hyperbolic Tangent activation function:
\(\text{STanh}(z) = a \tanh(bz)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.STanh(a=1.7, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.STanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ScaledExponentialLinearUnit(a: float = 1.67326, b: float = 1.0)[source]
Bases:
ModuleApplies the Scaled Exponential Linear Unit activation function:
\(\text{ScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.67326
b (float, optional) – Alpha parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ScaledExponentiallyRegularizedLinearUnit(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the Scaled Exponentially Regularized Linear Unit activation function:
\(\text{ScaledExponentiallyRegularizedLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ abz\exp(z), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Regularization parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentiallyRegularizedLinearUnit(a=1.5, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ScaledScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 1.0)[source]
Bases:
ModuleApplies the Scaled Scaled Exponential Linear Unit activation function:
\(\text{ScaledScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(cz) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SechSig[source]
Bases:
ModuleApplies the SechSig activation function:
\(\text{SechSig}(z) = (z + \text{sech}(z))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SechSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SelfArctan[source]
Bases:
ModuleApplies the SelfArctan activation function:
\(\text{SelfArctan}(z) = z \cdot \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SelfArctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Serf[source]
Bases:
ModuleApplies the Serf activation function:
\(\text{Serf}(z) = z \cdot \text{erf}(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Serf() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ShHardTanh(a: float = 0.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Shifted HardTanh activation function:
\[\begin{split}\text{ShHardTanh}(z) = \begin{cases} -1, & z < -1 - a, \\ z, & -1 - a \leq z \leq 1 - a, \\ 1, & z > 1 - a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ShHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ShHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ShiftedReLU(inplace: bool = False)[source]
Bases:
ModuleA Shifted ReLU is a simple translation of a ReLU and is defined as:
\(\text{ShiftedReLU}(x) = \text{max}(-1, x)\)
See: http://arxiv.org/abs/1511.07289
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.ShiftedScaledSigmoid(a: float = 1.0, b: float = 0.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Shifted Scaled Sigmoid activation function:
\(\text{ShiftedScaledSigmoid}(z) = \frac{1}{1 + \exp(-a(z-b))}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Shift parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ShiftedScaledSigmoid(a=2.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ShiftedScaledSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SiELU[source]
Bases:
ModuleApplies the SiELU activation function:
\(\text{SiELU}(z) = z \cdot \sigma\left(\sqrt{\frac{2}{\pi}} z + 0.044715 z^3\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SiELU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SigLin(a: float = 0.2, inplace: bool = False)[source]
Bases:
ModuleApplies the SigLin activation function:
\(\text{SigLin}(z) = \sigma(z) + az\)
- Parameters:
a (float, optional) – Linear coefficient. Default: 0.2
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigLin(a=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigLin(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Sigmoid(inplace: bool = False)[source]
Bases:
ModuleApplies the Sigmoid activation function:
\(\text{Sigmoid}(z) = \frac{1}{1 + \exp(-z)}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Sigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Sigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SigmoidAlgebraic(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Sigmoid Algebraic activation function:
\(\text{SigmoidAlgebraic}(z) = \frac{1}{1 + \exp\left(-\frac{z(1 + a|z|)}{1 + |z|(1 + a|z|)}\right)}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidAlgebraic(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigmoidAlgebraic(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SigmoidGumbel[source]
Bases:
ModuleApplies the Sigmoid Gumbel activation function:
\(\text{SigmoidGumbel}(z) = \frac{1}{1 + \exp(-z) \exp(-\exp(-z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidGumbel() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SigmoidTanhCombinations(g_func=<built-in method sigmoid of type object>, h_func=<built-in method tanh of type object>)[source]
Bases:
ModuleApplies the Sigmoid-Tanh Combinations activation function:
\(\text{SigmoidTanhCombinations}(z) = \begin{cases} g(z), & z \geq 0 \\ h(z), & z < 0 \end{cases}\)
where g(z) and h(z) are user-defined functions, defaulting to sigmoid and tanh respectively.
- Parameters:
g_func (callable, optional) – Function to use for positive inputs. Default: torch.sigmoid
h_func (callable, optional) – Function to use for negative inputs. Default: torch.tanh
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidTanhCombinations() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom functions >>> import torch.nn.functional as F >>> m = nn.SigmoidTanhCombinations(g_func=F.relu, h_func=torch.sigmoid) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SinLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Sinu-sigmoidal Linear Unit activation function:
\(\text{SinLU}(x) = (x + a \cdot \sin (b \cdot x)) \sigma (x)\)
- Parameters:
a (float, optional) – Initial value for sine function magnitude. Default: 1.0.
b (float, optional) – Initial value for sine function period. Default: 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = nn.SinLU(a=5.0, b=6.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SinSig[source]
Bases:
ModuleApplies the SinSig activation function:
\(\text{SinSig}(z) = z \cdot \sin\left(\frac{\pi}{2} \sigma(z)\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SinSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SincSigmoid[source]
Bases:
ModuleApplies the Sinc Sigmoid activation function:
\(\text{SincSigmoid}(z) = \text{sinc}(\sigma(z))\)
where \(\text{sinc}(x) = \frac{\sin(\pi x)}{\pi x}\) if \(x \neq 0\), and 1 if \(x = 0\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SincSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SineReLU(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the element-wise function:
\[\begin{split}\text{SineReLU}(z) = \begin{cases} z, & \text{if } z \geq 0 \\ a (\sin(z) - \cos(z)), & \text{if } z < 0 \end{cases}\end{split}\]- Parameters:
a (float, optional) – The scaling parameter for the negative inputs. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = torch_activation.SineReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SineReLU(a=0.5) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SlReLU(a=10.0, inplace: bool = False)[source]
Bases:
ModuleA Sloped ReLU (SlReLU) [242] is similar to the LReLU — whereas the LReLU parameterizes the slope for negative inputs, the SlReLU parameterizes the slope of ReLU for positive inputs. It is, therefore, defined as:
\[\begin{split}`\text{SlReLU}(z) = \begin{cases} a \cdot z, & z \geq 0, \\ 0, & z < 0, \end{cases}`\end{split}\]a is recommended to be from 1 to 10.
See: https://doi.org/10.1109/pimrc.2017.8292678
- Parameters:
a (float, optional) – The slope for positive inputs. Default: 10.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.SlReLU(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SlReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x)[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Smish(a: float = 1.0, b: float = 1.0)[source]
Bases:
ModuleApplies the Smish activation function:
\(\text{Smish}(z) = a \cdot z \cdot \tanh(\ln(1 + \sigma(b \cdot z)))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Smish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SmoothStep(a: float = 2.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Smooth Step activation function:
\(\text{SmoothStep}(z) = \begin{cases} 1, & z \geq \frac{a}{2} \\ \frac{2}{a^3} z^3 - \frac{3}{2a} z + \frac{1}{2}, & -\frac{a}{2} \leq z \leq \frac{a}{2} \\ 0, & z \leq -\frac{a}{2} \end{cases}\)
- Parameters:
a (float, optional) – Width parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SmoothStep(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SmoothStep(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SoftClipping(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Soft Clipping activation function:
\(\text{SoftClipping}(z) = \frac{1}{a} \ln\left(\frac{1 + \exp(az)}{1 + \exp(a(z-1))}\right)\)
- Parameters:
a (float, optional) – Sharpness parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftClipping(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftClipping(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SoftRootSign(a: float = 2.0, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Soft Root Sign activation function:
\(\text{SoftRootSign}(z) = \frac{z}{\sqrt[a]{1 + \exp\left(-\frac{z}{b}\right)}}\)
- Parameters:
a (float, optional) – Root parameter. Default: 2.0
b (float, optional) – Scale parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftRootSign(a=3.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftRootSign(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Softshrink(a: float = 0.5, inplace: bool = False)[source]
Bases:
ModuleApplies the Softshrink activation function:
\[\begin{split}\text{Softshrink}(z) = \begin{cases} z - a, & z > a, \\ 0, & -a \leq z \leq a, \\ z + a, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.Softshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Softshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Softsign[source]
Bases:
ModuleApplies the Softsign activation function:
\(\text{Softsign}(z) = \frac{z}{1 + |z|}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Softsign() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SoftsignRReLU(l: float = 0.125, u: float = 0.3333333333333333)[source]
Bases:
ModuleThe Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}`\text{S-RReLU}(z_i) = \begin{cases} \frac{1}{(1+z_i)^2} + z_i, & z_i \geq 0, \\ \frac{1}{(1+z_i)^2} + a_i z_i, & z_i < 0, \end{cases}`\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
See: http://dx.doi.org/10.1007/s00521-023-08565-2
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SqREU(inplace: bool = False)[source]
Bases:
ModuleApplies the SqREU (Square Rectified Exponential Unit) activation function:
\(\text{SqREU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqREU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqREU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SqSoftplus(inplace: bool = False)[source]
Bases:
ModuleApplies the SqSoftplus (Square Softplus) activation function:
\(\text{SqSoftplus}(z) = \begin{cases} z, & z > \frac{1}{2} \\ z + \frac{(z + \frac{1}{2})^2}{2}, & -\frac{1}{2} \leq z \leq \frac{1}{2} \\ 0, & z < -\frac{1}{2} \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqSoftplus() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqSoftplus(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SquaredReLU(inplace: bool = False)[source]
Bases:
ModuleApplies the SquaredReLU activation function:
\(\text{SquaredReLU}(z) = \begin{cases} z^2, & z > 0 \\ 0, & z \leq 0 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SquaredReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SquaredReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Squish(inplace: bool = False)[source]
Bases:
ModuleApplies the Squish activation function:
\(\text{Squish}(z) = \begin{cases} z + \frac{z^2}{32}, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Squish() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Squish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Suish[source]
Bases:
ModuleApplies the Suish activation function:
\(\text{Suish}(z) = \max(z, z \cdot \exp(-|z|))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Suish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SvHardTanh(a: float = 0.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Shifted HardTanh activation function:
\[\begin{split}\text{SvHardTanh}(z) = \begin{cases} -1 + a, & z < -1, \\ z + a, & -1 \leq z \leq 1, \\ 1 + a, & z > 1, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.SvHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SvHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SwAT[source]
Bases:
ModuleApplies the SwAT activation function:
\(\text{SwAT}(z) = z \cdot \frac{1}{1 + \exp(-\arctan(|z|))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SwAT() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SwiGLU(dim: int = -1)[source]
Bases:
ModuleApplies the Swish-GELU function:
\(\text{SwiGLU}(z, z') = z \otimes \text{swish}(z')\)
where \(\text{swish}(x) = x \cdot \sigma(x)\) and \(\otimes\) is element-wise multiplication.
- Parameters:
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = SwiGLU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SymmetricalGaussianErrorLinearUnit(a: float = 1.0)[source]
Bases:
ModuleApplies the Symmetrical Gaussian Error Linear Unit activation function:
\(\text{SGELU}(z) = a \cdot z \cdot \text{erf}\left(\frac{z}{\sqrt{2}}\right)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SymmetricalGaussianErrorLinearUnit(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.SymmetricalMSAF(a: float = 1.0)[source]
Bases:
ModuleApplies the Symmetrical Multistate Activation Function:
\(\text{SymmetricalMSAF}(z) = -1 + \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z-a)}\)
- Parameters:
a (float, optional) – Shift parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SymmetricalMSAF(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TRec(a: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Truncated Rectified activation function:
\[\begin{split}\text{TRec}(z) = \begin{cases} z, & z > a, \\ 0, & z \leq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.TRec() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TRec(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TangentBipolarSigmoidReLU[source]
Bases:
ModuleApplies the Tangent Bipolar Sigmoid ReLU activation function:
\(\text{TangentBipolarSigmoidReLU}(z) = z \cdot \tanh\left(\frac{1 - \exp(-z)}{1 + \exp(-z)}\right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentBipolarSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TangentSigmoidReLU[source]
Bases:
ModuleApplies the Tangent Sigmoid ReLU activation function:
\(\text{TangentSigmoidReLU}(z) = z \cdot \tanh(\sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.Tanh(inplace: bool = False)[source]
Bases:
ModuleApplies the Tanh activation function:
\(\text{Tanh}(z) = \tanh(z)\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Tanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Tanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TanhExp[source]
Bases:
ModuleApplies the TanhExp activation function:
\(\text{TanhExp}(z) = z \cdot \tanh(\exp(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhExp() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TanhLinearUnit[source]
Bases:
ModuleApplies the Tanh Linear Unit activation function:
\(\text{TanhLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{2}{1 + \exp(-z)} - 1, & z < 0 \end{cases} = \begin{cases} z, & z \geq 0 \\ \tanh\left(\frac{z}{2}\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TanhSig[source]
Bases:
ModuleApplies the TanhSig activation function:
\(\text{TanhSig}(z) = (z + \tanh(z))\sigma(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TanhSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TripleStateSigmoid(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Triple State Sigmoid activation function:
\(\text{TripleStateSigmoid}(z) = \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)}\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TripleStateSigmoid(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.TripleStateSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.TripleStateSwish(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Triple State Swish activation function:
\(\text{TSS}(z) = z \cdot \frac{1}{1 + \exp(-z)} \left( \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)} \right)\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TripleStateSwish(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.UnnamedSigmoid1(a: float = 2.0)[source]
Bases:
Module- Note:
The name “UnnamesSigmoid1” derived from “3.2.25 Rootsig and others” entry, particularly the first from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 1 activation function:
\(\text{UnnamedSigmoid1}(z) = z \cdot \text{sgn}(z) \sqrt{z^{-a} - a^{-2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 2.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid1(a=3.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.UnnamedSigmoid2(a: float = 1.0)[source]
Bases:
Module- Note:
The name “UnnamesSigmoid2” derived from “3.2.25 Rootsig and others” entry, particularly the second from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 2 activation function:
\(\text{UnnamedSigmoid2}(z) = \frac{az}{1 + |az|}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid2(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.UnnamedSigmoid3(a: float = 1.0)[source]
Bases:
Module- Note:
The name “UnnamedSigmoid3” derived from “3.2.25 Rootsig and others” entry, particularly the third from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 3 activation function:
\(\text{UnnamedSigmoid3}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid3(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.VLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Bases:
ModuleApplies the element-wise function:
\(\text{VLU}(x) = \text{ReLU}(x) + a \sin(bx) = \max(0, x) + a \sin(bx)\)
- Parameters:
a (float) – Scaling factor for the sine component. Default:
1.0b (float) – Frequency multiplier for the sine component. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = VLU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.VReLU(inplace: bool = False)[source]
Bases:
ModuleApplies the V-shaped ReLU activation function:
\[\begin{split}\text{vReLU}(z) = |z| = \begin{cases} z, & z \geq 0, \\ -z, & z < 0, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.VReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.VReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.VariantSigmoidFunction(a: float = 1.0, b: float = 1.0, c: float = 0.0, inplace: bool = False)[source]
Bases:
ModuleApplies the Variant Sigmoid Function activation:
\(\text{VariantSigmoidFunction}(z) = \frac{a}{1 + \exp(-bz)} - c\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
c (float, optional) – Offset parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.VariantSigmoidFunction(a=2.0, b=1.5, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.VariantSigmoidFunction(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
ReLU-based
- class torch_activation.classical.relu.AbsLU(a: float = 0.5, inplace: bool = False)[source]
Applies the Absolute Linear Unit activation function:
\[\begin{split}\text{AbsLU}(z) = \begin{cases} z, & z \geq 0, \\ a|z|, & z < 0, \end{cases}\end{split}\]where \(a \in [0, 1]\).
- Parameters:
a (float, optional) – Scaling parameter for negative inputs. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.AbsLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.AbsLU(a=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.BLReLU(a: float = 0.1, b: float = 1.0, inplace: bool = False)[source]
Applies the Bounded Leaky ReLU activation function:
\[\begin{split}\text{BLReLU}(z) = \begin{cases} az, & z \leq 0, \\ z, & 0 < z < b, \\ az + c, & z \geq b, \end{cases}\end{split}\]where \(c = (1 - a)b\).
- Parameters:
a (float, optional) – Slope parameter for negative and large positive inputs. Default:
0.1b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.BLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BLReLU(a=0.2, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.BReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Bounded ReLU activation function:
\[\begin{split}\text{BReLU}(z) = \min(\max(0, z), a) = \begin{cases} 0, & z \leq 0, \\ z, & 0 < z < a, \\ a, & z \geq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Upper bound for the function’s output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.BReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.BReLU(a=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.CReLU(dim: int = 0)[source]
Applies the Concatenated Rectified Linear Unit activation function.
\(\text{CReLU}(x) = \text{ReLU}(x) \oplus \text{ReLU}(-x)\)
- Parameters:
dim (int, optional) – Dimension along which to concatenate in the output tensor. Default: 1
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.CReLU() >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = torch_activation.CReLU(inplace=True) >>> x = torch.randn(2, 3, 4) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.HardSigmoid(version: str = 'v1', inplace: bool = False)[source]
Applies the Hard Sigmoid activation function:
\(\text{HardSigmoid}(z) = \max(0, \min(\frac{z+1}{2}, 1))\)
or alternatively:
\(\text{HardSigmoid}(z) = \max(0, \min(0.2z + 0.5, 1))\)
- Parameters:
version (str, optional) – Version of hard sigmoid to use (‘v1’ or ‘v2’). Default:
'v1'inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.HardSigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSigmoid(version='v2', inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.HardSwish(inplace: bool = False)[source]
Applies the Hard Swish activation function:
\[\begin{split}\text{Hard swish}(z) = z \cdot \begin{cases} 0, & z \leq -3, \\ 1, & z \geq 3, \\ \frac{z}{6} + \frac{1}{2}, & -3 < z < 3, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.HardSwish() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardSwish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.HardTanh(a: float = -1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the HardTanh activation function:
\[\begin{split}\text{HardTanh}(z) = \begin{cases} a, & z < a, \\ z, & a \leq z \leq b, \\ b, & z > b, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Lower bound of the linear region. Default:
-1.0b (float, optional) – Upper bound of the linear region. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.HardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HardTanh(a=-2.0, b=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.Hardshrink(a: float = 0.5, inplace: bool = False)[source]
Applies the Hardshrink activation function:
\[\begin{split}\text{Hardshrink}(z) = \begin{cases} z, & z > a, \\ 0, & -a \leq z \leq a, \\ z, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.Hardshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Hardshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.LReLU(a: float = 100.0, inplace: bool = False)[source]
Applies the Leaky ReLU activation function.
\[\begin{split}\text{LReLU}(z) = \begin{cases} z, & z \geq 0, \\ \frac{z}{a}, & z < 0, \end{cases}\end{split}\]where \(a\) is recommended to be 100.
- Parameters:
a (float, optional) – The denominator for negative inputs. Default:
100.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.LReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LReLU(a=50.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.LSPTLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Linear Symmetric Piecewise Triangular Linear Unit activation function:
\[\begin{split}\text{LSPTLU}(z) = \begin{cases} 0.2z, & z < 0, \\ z, & 0 \leq z \leq a, \\ 2a - z, & a < z \leq 2a, \\ 0, & z > 2a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the shape. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.LSPTLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.LSPTLU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.MReLU(inplace: bool = False)[source]
Applies the Mirrored Rectified Linear Unit activation function:
\[\begin{split}\text{mReLU}(z) = \min(\text{ReLU}(1 - z), \text{ReLU}(1 + z)) = \begin{cases} 1 + z, & -1 \leq z \leq 0, \\ 1 - z, & 0 < z \leq 1, \\ 0, & \text{otherwise}, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.MReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.MReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.Minsin(inplace: bool = False)[source]
Applies the element-wise function:
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = Minsin() >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.NLReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the Natural-Logarithm-ReLU activation function:
\(\text{NLReLU}(z) = \ln(a \cdot \max(0, z) + 1)\)
- Parameters:
a (float, optional) – Scaling factor for the ReLU output. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.NLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NLReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.NReLU(sigma: float = 0.1, inplace: bool = False)[source]
Applies the Noisy ReLU activation function.
\[\text{NReLU}(z) = \max(0, z + a)\]where \(a \sim N(0, \sigma(z))\) is sampled from a Gaussian distribution.
- Parameters:
sigma (float, optional) – Standard deviation for the noise. Default:
0.1inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.NReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.NReLU(sigma=0.2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.OLReLU(l: float = 3.0, u: float = 8.0, inplace: bool = False)[source]
Applies the Optimized Leaky ReLU activation function.
\[\begin{split}\text{OLReLU}(z) = \begin{cases} z, & z \geq 0, \\ z \cdot \exp(-a), & z < 0, \end{cases}\end{split}\]where \(a = \frac{u+l}{u-l}\).
- Parameters:
l (float, optional) – Lower bound parameter. Default:
3.0u (float, optional) – Upper bound parameter. Default:
8.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.OLReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.OLReLU(l=2.0, u=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.PReNU(a: float = 0.25, inplace: bool = False)[source]
Applies the Parametric Rectified Non-linear Unit activation function:
\[\begin{split}\text{PReNU}(z) = \begin{cases} z - a \ln(z + 1), & z \geq 0, \\ 0, & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Parameter controlling the logarithmic term. Default:
0.25inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.PReNU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PReNU(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.PanFunction(a: float = 1.0, inplace: bool = False)[source]
Applies the Pan activation function:
\[\begin{split}\text{Pan function}(z) = \begin{cases} z - a, & z \geq a, \\ 0, & -a < z < a, \\ -z - a, & z \leq -a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.PanFunction() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.PanFunction(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.RReLU(l: float = 3.0, u: float = 8.0, inplace: bool = False)[source]
Applies the Randomized Leaky ReLU activation function.
\[\begin{split}\text{RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ z_i a_i, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled from a uniform distribution \(U(l, u)\), with recommended values \(U(3, 8)\).
- Parameters:
l (float, optional) – Lower bound of the uniform distribution. Default:
3.0u (float, optional) – Upper bound of the uniform distribution. Default:
8.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.RReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RReLU(l=2.0, u=6.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.RTReLU(sigma: float = 0.75, inplace: bool = False)[source]
Applies the Randomly Translational ReLU activation function:
\[\begin{split}\text{RT-ReLU}(z_i) = \begin{cases} z_i + a_i, & z_i + a_i \geq 0, \\ 0, & z_i + a_i < 0, \end{cases}\end{split}\]where \(a_i \sim N(0, \sigma^2)\) is sampled from a Gaussian distribution.
- Parameters:
sigma (float, optional) – Standard deviation for the Gaussian noise. Default:
0.75inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.RTReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.RTReLU(sigma=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.ReLUN(n: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\(\text{ReLUN}(x) = \min(\text{ReLU}(x), n)\)
- Parameters:
n (float, optional) – Upper bound for the function’s output. Default is 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ReLUN(n=6.0) # ReLU6 >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReLUN(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.ReSP(a: float = 1.7, inplace: bool = False)[source]
Applies the Rectified Softplus activation function:
\[\begin{split}\text{ReSP}(z) = \begin{cases} az + \ln(2), & z \geq 0, \\ \ln(1 + \exp(z)), & z < 0, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Scaling factor for positive inputs. Default:
1.7inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ReSP() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ReSP(a=1.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SCAA(channels: int, kernel_size: int = 3, padding: int = 1)[source]
Applies the Spatial Context-Aware Activation function:
\(\text{SCAA}(X) = \max(X, f_{DW}(X))\)
where \(f_{DW}\) is a depthwise convolution operation.
- Parameters:
channels (int) – Number of input channels
kernel_size (int, optional) – Size of the convolving kernel. Default:
3padding (int, optional) – Padding added to all sides of the input. Default:
1
- Shape:
Input: \((N, C, H, W)\) or \((C, H, W)\)
Output: Same shape as the input
Examples:
>>> m = torch_activation.SCAA(channels=64) >>> x = torch.randn(1, 64, 28, 28) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SLU(inplace: bool = False)[source]
Applies the Softplus Linear Unit activation function:
\[\begin{split}\text{SLU}(z) = \begin{cases} az, & z \geq 0, \\ b \ln(\exp(z) + 1) - c, & z < 0, \end{cases}\end{split}\]which simplifies to:
\[\begin{split}\text{SLU}(z) = \begin{cases} z, & z \geq 0, \\ 2 \ln(\frac{\exp(z) + 1}{2}), & z < 0, \end{cases}\end{split}\]where \(a=1, b=2, c=2\ln(2)\).
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.SLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SRReLU(l: float = 0.125, u: float = 0.3333333333333333, inplace: bool = False)[source]
The Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}\text{S-RReLU}(z_i) = \begin{cases} z_i, & z_i \geq 0, \\ \frac{z_i}{a_i}, & z_i < 0, \end{cases}\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.SRReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SRReLU(l=1/4, u=1/2, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.ShHardTanh(a: float = 0.0, inplace: bool = False)[source]
Applies the Shifted HardTanh activation function:
\[\begin{split}\text{ShHardTanh}(z) = \begin{cases} -1, & z < -1 - a, \\ z, & -1 - a \leq z \leq 1 - a, \\ 1, & z > 1 - a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.ShHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.ShHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.ShiftedReLU(inplace: bool = False)[source]
A Shifted ReLU is a simple translation of a ReLU and is defined as:
\(\text{ShiftedReLU}(x) = \text{max}(-1, x)\)
See: http://arxiv.org/abs/1511.07289
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SineReLU(a: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\[\begin{split}\text{SineReLU}(z) = \begin{cases} z, & \text{if } z \geq 0 \\ a (\sin(z) - \cos(z)), & \text{if } z < 0 \end{cases}\end{split}\]- Parameters:
a (float, optional) – The scaling parameter for the negative inputs. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = torch_activation.SineReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SineReLU(a=0.5) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SlReLU(a=10.0, inplace: bool = False)[source]
A Sloped ReLU (SlReLU) [242] is similar to the LReLU — whereas the LReLU parameterizes the slope for negative inputs, the SlReLU parameterizes the slope of ReLU for positive inputs. It is, therefore, defined as:
\[\begin{split}`\text{SlReLU}(z) = \begin{cases} a \cdot z, & z \geq 0, \\ 0, & z < 0, \end{cases}`\end{split}\]a is recommended to be from 1 to 10.
See: https://doi.org/10.1109/pimrc.2017.8292678
- Parameters:
a (float, optional) – The slope for positive inputs. Default: 10.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*, C, *)\) where \(*\) means any number of additional dimensions
Output: \((*, 2C, *)\)
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.SlReLU(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SlReLU(a=2.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x)[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.Softshrink(a: float = 0.5, inplace: bool = False)[source]
Applies the Softshrink activation function:
\[\begin{split}\text{Softshrink}(z) = \begin{cases} z - a, & z > a, \\ 0, & -a \leq z \leq a, \\ z + a, & z < -a, \end{cases}\end{split}\]where \(a > 0\).
- Parameters:
a (float, optional) – Threshold parameter. Default:
0.5inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.Softshrink() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.Softshrink(a=1.0, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SoftsignRReLU(l: float = 0.125, u: float = 0.3333333333333333)[source]
The Softsign Randomized Leaky ReLU (S-RReLU) is defined as:
\[\begin{split}`\text{S-RReLU}(z_i) = \begin{cases} \frac{1}{(1+z_i)^2} + z_i, & z_i \geq 0, \\ \frac{1}{(1+z_i)^2} + a_i z_i, & z_i < 0, \end{cases}`\end{split}\]where \(a_i\) is sampled for each epoch and neuron i from the uniform distribution \(a_i \sim U(l, u)\) where \(l < u\) and \(l, u \in (0, \infty)\).
See: http://dx.doi.org/10.1007/s00521-023-08565-2
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
- Parameters:
l (float, optional) – Lower bound of the uniform distribution (default: 1/8).
u (float, optional) – Upper bound of the uniform distribution (default: 1/3).
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SquaredReLU(inplace: bool = False)[source]
Applies the element-wise function:
\(\text{SquaredReLU}(x) = \text{ReLU}(x)^2\)
- Parameters:
inplace – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:

Examples:
>>> m = torch_activation.SquaredReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SquaredReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.SvHardTanh(a: float = 0.0, inplace: bool = False)[source]
Applies the Shifted HardTanh activation function:
\[\begin{split}\text{SvHardTanh}(z) = \begin{cases} -1 + a, & z < -1, \\ z + a, & -1 \leq z \leq 1, \\ 1 + a, & z > 1, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Shift parameter. Default:
0.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.SvHardTanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.SvHardTanh(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.TRec(a: float = 1.0, inplace: bool = False)[source]
Applies the Truncated Rectified activation function:
\[\begin{split}\text{TRec}(z) = \begin{cases} z, & z > a, \\ 0, & z \leq a, \end{cases}\end{split}\]- Parameters:
a (float, optional) – Threshold parameter. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.TRec() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.TRec(a=0.5, inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.VLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the element-wise function:
\(\text{VLU}(x) = \text{ReLU}(x) + a \sin(bx) = \max(0, x) + a \sin(bx)\)
- Parameters:
a (float) – Scaling factor for the sine component. Default:
1.0b (float) – Frequency multiplier for the sine component. Default:
1.0inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function:
Examples:
>>> m = VLU(a=1.0, b=1.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.relu.VReLU(inplace: bool = False)[source]
Applies the V-shaped ReLU activation function:
\[\begin{split}\text{vReLU}(z) = |z| = \begin{cases} z, & z \geq 0, \\ -z, & z < 0, \end{cases}\end{split}\]- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = torch_activation.VReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.VReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Sigmoid-based
- class torch_activation.classical.sigmoid_family.Arctan[source]
Applies the Arctan activation function:
\(\text{Arctan}(z) = \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Arctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ArctanGR[source]
Applies the ArctanGR activation function:
\(\text{ArctanGR}(z) = \frac{\arctan(z)}{1 + \sqrt{2}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ArctanGR() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ComplementaryLogLog[source]
Applies the Complementary LogLog activation function:
\(\text{ComplementaryLogLog}(z) = 1 - \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ElliottActivationFunction[source]
Applies the Elliott Activation Function:
\(\text{ElliottActivationFunction}(z) = \frac{0.5z}{1 + |z|} + 0.5\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ElliottActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Hexpo(a: float = 1.0, b: float = 1.0, c: float = 1.0, d: float = 1.0, inplace: bool = False)[source]
Applies the Hexpo activation function:
\(\text{Hexpo}(z) = \begin{cases} -a \exp\left(-\frac{z}{b}\right) - 1, & z \geq 0 \\ c \exp\left(-\frac{z}{d}\right) - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Positive scale parameter. Default: 1.0
b (float, optional) – Positive decay parameter. Default: 1.0
c (float, optional) – Negative scale parameter. Default: 1.0
d (float, optional) – Negative decay parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Hexpo(a=1.5, b=0.5, c=2.0, d=0.7) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Hexpo(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ImprovedLogisticSigmoid(a: float = 0.2, b: float = 2.0, inplace: bool = False)[source]
Applies the Improved Logistic Sigmoid activation function:
\(\text{ImprovedLogisticSigmoid}(z) = \begin{cases} a(z-b) + \sigma(b), & z \geq b \\ \sigma(z), & -b < z < b \\ a(z+b) + \sigma(-b), & z \leq -b \end{cases}\)
- Parameters:
a (float, optional) – Slope parameter. Default: 0.2
b (float, optional) – Threshold parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ImprovedLogisticSigmoid(a=0.1, b=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ImprovedLogisticSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.LogLog[source]
Applies the LogLog activation function:
\(\text{LogLog}(z) = \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ModifiedComplementaryLogLog[source]
Applies the Modified Complementary LogLog activation function:
\(\text{ModifiedComplementaryLogLog}(z) = 1 - 2\exp(-0.7\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ModifiedComplementaryLogLog() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.MultistateActivationFunction(a: float = 0.0, b: list = None)[source]
Applies the Multistate Activation Function:
\(\text{MultistateActivationFunction}(z) = a + \sum_{k=1}^N \frac{1}{1 + \exp(-z+b_k)}\)
- Parameters:
a (float, optional) – Offset parameter. Default: 0.0
b (list of float, optional) – List of shift parameters. Default: [1.0, 2.0]
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MultistateActivationFunction(a=0.5, b=[0.5, 1.5, 2.5]) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.NewSigmoid[source]
Applies the New Sigmoid activation function:
\(\text{NewSigmoid}(z) = \frac{\exp(z) - \exp(-z)}{2(\exp(2z) + \exp(-2z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.NewSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ParametricSechSig(a: float = 1.0)[source]
Applies the Parametric SechSig activation function:
\(\text{ParametricSechSig}(z) = (z + a\cdot \text{sech}(z+a))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricSechSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ParametricTanhSig(a: float = 1.0)[source]
Applies the Parametric TanhSig activation function:
\(\text{ParametricTanhSig}(z) = (z + a\cdot \tanh(z+a))\sigma(z)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ParametricTanhSig(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.PenalizedHyperbolicTangent(a: float = 2.0, inplace: bool = False)[source]
Applies the Penalized Hyperbolic Tangent activation function:
\(\text{PenalizedHyperbolicTangent}(z) = \begin{cases} \tanh(z), & z \geq 0 \\ \frac{\tanh(z)}{a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Penalty factor for negative inputs. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.PenalizedHyperbolicTangent(a=3.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.PenalizedHyperbolicTangent(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Root2sigmoid[source]
Applies the Root2sigmoid activation function:
\(\text{Root2sigmoid}(z) = \frac{\sqrt{2}z}{\sqrt{2^{-2z}} + \sqrt{2^{2z}}}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Root2sigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Rootsig(a: float = 1.0)[source]
Applies the Rootsig activation function:
\(\text{Rootsig}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Rootsig(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.STanh(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Scaled Hyperbolic Tangent activation function:
\(\text{STanh}(z) = a \tanh(bz)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.STanh(a=1.7, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.STanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SechSig[source]
Applies the SechSig activation function:
\(\text{SechSig}(z) = (z + \text{sech}(z))\sigma(z)\)
where \(\text{sech}(z) = \frac{2}{e^z + e^{-z}}\) is the hyperbolic secant.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SechSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.ShiftedScaledSigmoid(a: float = 1.0, b: float = 0.0, inplace: bool = False)[source]
Applies the Shifted Scaled Sigmoid activation function:
\(\text{ShiftedScaledSigmoid}(z) = \frac{1}{1 + \exp(-a(z-b))}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Shift parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ShiftedScaledSigmoid(a=2.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ShiftedScaledSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SigLin(a: float = 0.2, inplace: bool = False)[source]
Applies the SigLin activation function:
\(\text{SigLin}(z) = \sigma(z) + az\)
- Parameters:
a (float, optional) – Linear coefficient. Default: 0.2
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigLin(a=0.1) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigLin(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Sigmoid(inplace: bool = False)[source]
Applies the Sigmoid activation function:
\(\text{Sigmoid}(z) = \frac{1}{1 + \exp(-z)}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Sigmoid() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Sigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SigmoidAlgebraic(a: float = 1.0, inplace: bool = False)[source]
Applies the Sigmoid Algebraic activation function:
\(\text{SigmoidAlgebraic}(z) = \frac{1}{1 + \exp\left(-\frac{z(1 + a|z|)}{1 + |z|(1 + a|z|)}\right)}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidAlgebraic(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SigmoidAlgebraic(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SigmoidGumbel[source]
Applies the Sigmoid Gumbel activation function:
\(\text{SigmoidGumbel}(z) = \frac{1}{1 + \exp(-z) \exp(-\exp(-z))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidGumbel() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SigmoidTanhCombinations(g_func=<built-in method sigmoid of type object>, h_func=<built-in method tanh of type object>)[source]
Applies the Sigmoid-Tanh Combinations activation function:
\(\text{SigmoidTanhCombinations}(z) = \begin{cases} g(z), & z \geq 0 \\ h(z), & z < 0 \end{cases}\)
where g(z) and h(z) are user-defined functions, defaulting to sigmoid and tanh respectively.
- Parameters:
g_func (callable, optional) – Function to use for positive inputs. Default: torch.sigmoid
h_func (callable, optional) – Function to use for negative inputs. Default: torch.tanh
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SigmoidTanhCombinations() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom functions >>> import torch.nn.functional as F >>> m = nn.SigmoidTanhCombinations(g_func=F.relu, h_func=torch.sigmoid) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SincSigmoid[source]
Applies the Sinc Sigmoid activation function:
\(\text{SincSigmoid}(z) = \text{sinc}(\sigma(z))\)
where \(\text{sinc}(x) = \frac{\sin(\pi x)}{\pi x}\) if \(x \neq 0\), and 1 if \(x = 0\).
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SincSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SmoothStep(a: float = 2.0, inplace: bool = False)[source]
Applies the Smooth Step activation function:
\(\text{SmoothStep}(z) = \begin{cases} 1, & z \geq \frac{a}{2} \\ \frac{2}{a^3} z^3 - \frac{3}{2a} z + \frac{1}{2}, & -\frac{a}{2} \leq z \leq \frac{a}{2} \\ 0, & z \leq -\frac{a}{2} \end{cases}\)
- Parameters:
a (float, optional) – Width parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SmoothStep(a=1.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SmoothStep(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SoftClipping(a: float = 1.0, inplace: bool = False)[source]
Applies the Soft Clipping activation function:
\(\text{SoftClipping}(z) = \frac{1}{a} \ln\left(\frac{1 + \exp(az)}{1 + \exp(a(z-1))}\right)\)
- Parameters:
a (float, optional) – Sharpness parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftClipping(a=2.0) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftClipping(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SoftRootSign(a: float = 2.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Soft Root Sign activation function:
\(\text{SoftRootSign}(z) = \frac{z}{\sqrt[a]{1 + \exp\left(-\frac{z}{b}\right)}}\)
- Parameters:
a (float, optional) – Root parameter. Default: 2.0
b (float, optional) – Scale parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SoftRootSign(a=3.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SoftRootSign(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Softsign[source]
Applies the Softsign activation function:
\(\text{Softsign}(z) = \frac{z}{1 + |z|}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Softsign() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.SymmetricalMSAF(a: float = 1.0)[source]
Applies the Symmetrical Multistate Activation Function:
\(\text{SymmetricalMSAF}(z) = -1 + \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z-a)}\)
- Parameters:
a (float, optional) – Shift parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SymmetricalMSAF(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.Tanh(inplace: bool = False)[source]
Applies the Tanh activation function:
\(\text{Tanh}(z) = \tanh(z)\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Tanh() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Tanh(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.TanhSig[source]
Applies the TanhSig activation function:
\(\text{TanhSig}(z) = (z + \tanh(z))\sigma(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TanhSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.TripleStateSigmoid(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Applies the Triple State Sigmoid activation function:
\(\text{TripleStateSigmoid}(z) = \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)}\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.TripleStateSigmoid(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.TripleStateSigmoid(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.UnnamedSigmoid1(a: float = 2.0)[source]
- Note:
The name “UnnamesSigmoid1” derived from “3.2.25 Rootsig and others” entry, particularly the first from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 1 activation function:
\(\text{UnnamedSigmoid1}(z) = z \cdot \text{sgn}(z) \sqrt{z^{-a} - a^{-2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 2.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid1(a=3.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.UnnamedSigmoid2(a: float = 1.0)[source]
- Note:
The name “UnnamesSigmoid2” derived from “3.2.25 Rootsig and others” entry, particularly the second from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 2 activation function:
\(\text{UnnamedSigmoid2}(z) = \frac{az}{1 + |az|}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid2(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.UnnamedSigmoid3(a: float = 1.0)[source]
- Note:
The name “UnnamedSigmoid3” derived from “3.2.25 Rootsig and others” entry, particularly the third from from “others” part. Leave it here until I find a better name.
Applies the Unnamed Sigmoid 3 activation function:
\(\text{UnnamedSigmoid3}(z) = \frac{az}{\sqrt{1 + a^2z^2}}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.UnnamedSigmoid3(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_family.VariantSigmoidFunction(a: float = 1.0, b: float = 1.0, c: float = 0.0, inplace: bool = False)[source]
Applies the Variant Sigmoid Function activation:
\(\text{VariantSigmoidFunction}(z) = \frac{a}{1 + \exp(-bz)} - c\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Slope parameter. Default: 1.0
c (float, optional) – Offset parameter. Default: 0.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.VariantSigmoidFunction(a=2.0, b=1.5, c=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.VariantSigmoidFunction(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Sigmoid-weighted
- class torch_activation.classical.sigmoid_weighted.ArctanSiLU[source]
Applies the Arctan SiLU activation function:
\(\text{ArctanSiLU}(z) = \arctan(z) \cdot \frac{1}{1 + \exp(-z)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ArctanSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.CauchyLinearUnit[source]
Applies the Cauchy Linear Unit activation function:
\(\text{CaLU}(z) = z \cdot \Phi_{\text{Cauchy}}(z) = z \cdot \left( \frac{\arctan(z)}{\pi} + \frac{1}{2} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CauchyLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.CoLU(inplace=False)[source]
Applies the Collapsing Linear Unit activation function:
\(\text{CoLU}(x) = \frac{x}{1-x \cdot e^{-(x + e^x)}}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.CoLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.CoLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.CollapsingLinearUnit(inplace=False)[source]
Applies the Collapsing Linear Unit activation function:
\(\text{CoLU}(z) = z \cdot \frac{1}{1 - z \exp(-(z + \exp(z)))}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = CollapsingLinearUnit() >>> x = torch.randn(2) >>> output = m(x) >>> m = CollapsingLinearUnit(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.DerivativeOfSiLU[source]
Applies the Derivative of SiLU activation function:
\(\text{DerivativeOfSiLU}(z) = \sigma(z) \cdot (1 + z \cdot (1 - \sigma(z)))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.DerivativeOfSigmoidFunction[source]
Applies the Derivative of Sigmoid Function activation:
\(\text{DerivativeOfSigmoidFunction}(z) = \exp(-z) \cdot (\sigma(z))^2\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DerivativeOfSigmoidFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.DoubleSiLU[source]
Applies the Double SiLU activation function:
\(\text{DoubleSiLU}(z) = z \cdot \frac{1}{1 + \exp\left(-z \cdot \frac{1}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DoubleSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.EfficientAsymmetricNonlinearActivationFunction[source]
Applies the Efficient Asymmetric Nonlinear Activation Function:
\(\text{EfficientAsymmetricNonlinearActivationFunction}(z) = z \cdot \frac{\exp(z)}{\exp(z) + 2}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = EfficientAsymmetricNonlinearActivationFunction() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.ExpExpish[source]
Applies the ExpExpish activation function:
\(\text{ExpExpish}(z) = z \cdot \exp(-\exp(-z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExpExpish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.ExponentialSwish[source]
Applies the Exponential Swish activation function:
\(\text{ExponentialSwish}(z) = \exp(-z) \cdot \sigma(z)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.GaussianErrorLinearUnit[source]
Applies the Gaussian Error Linear Unit activation function:
\(\text{GELU}(z) = z \cdot \Phi(z) = z \cdot \frac{1}{2} \left( 1 + \text{erf}\left(\frac{z}{\sqrt{2}}\right) \right)\)
This is a wrapper around PyTorch’s native F.gelu implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GaussianErrorLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.GeneralizedSwish[source]
Applies the Generalized Swish activation function:
\(\text{GSwish}(z) = z \cdot \sigma(\exp(-z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = GeneralizedSwish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Gish[source]
Applies the Gish activation function:
\(\text{Gish}(z) = z \cdot \ln(2 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Gish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.HyperbolicTangentSiLU[source]
Applies the Hyperbolic Tangent SiLU activation function:
\(\text{HyperbolicTangentSiLU}(z) = \frac{\exp\left(\frac{z}{1 + \exp(-z)}\right) - \exp\left(-\frac{z}{1 + \exp(-z)}\right)}{\exp\left(\frac{z}{1 + \exp(-z)}\right) + \exp\left(\frac{z}{1 + \exp(-z)}\right)}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HyperbolicTangentSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.LaplaceLinearUnit[source]
Applies the Laplace Linear Unit activation function:
\(\text{LaLU}(z) = z \cdot \Phi_{\text{Laplace}}(z) = z \cdot \begin{cases} 1 - \frac{1}{2} \exp(-z), & z \geq 0 \\ \frac{1}{2} \exp(z), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LaplaceLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.LinearlyScaledHyperbolicTangent[source]
Applies the Linearly Scaled Hyperbolic Tangent activation function:
\(\text{LinearlyScaledHyperbolicTangent}(z) = z \cdot \tanh(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LinearlyScaledHyperbolicTangent() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.LogLogish[source]
Applies the LogLogish activation function:
\(\text{LogLogish}(z) = z \cdot (1 - \exp(-\exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogLogish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.LogSigmoid[source]
Applies the LogSigmoid activation function:
\(\text{LogSigmoid}(z) = \ln(\sigma(z)) = \ln\left(\frac{1}{1 + \exp(-z)}\right)\)
This is a wrapper around PyTorch’s native F.logsigmoid implementation.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LogSigmoid() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Logish[source]
Applies the Logish activation function:
\(\text{Logish}(z) = z \cdot \ln(1 + \sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Logish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Mish[source]
Applies the Mish activation function:
\(\text{Mish}(z) = z \cdot \tanh(\text{softplus}(z)) = z \cdot \tanh(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Mish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.ModifiedSiLU[source]
Applies the Modified SiLU activation function:
\(\text{ModifiedSiLU}(z) = z \cdot \sigma(z) + \exp\left(-\frac{z^2}{4}\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ModifiedSiLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.ParametricLogish(a: float = 1.0, b: float = 1.0)[source]
Applies the Parametric Logish activation function:
\(\text{ParametricLogish}(z_i) = a \cdot z_i \cdot \ln(1 + \sigma(b \cdot z_i))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ParametricLogish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Phish[source]
Applies the Phish activation function:
\(\text{Phish}(z) = z \cdot \tanh(\text{GELU}(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Phish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.RectifiedHyperbolicSecant[source]
Applies the Rectified Hyperbolic Secant activation function:
\(\text{RectifiedHyperbolicSecant}(z) = z \cdot \text{sech}(z)\)
where sech is the hyperbolic secant function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RectifiedHyperbolicSecant() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SelfArctan[source]
Applies the SelfArctan activation function:
\(\text{SelfArctan}(z) = z \cdot \arctan(z)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SelfArctan() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Serf[source]
Applies the Serf activation function:
\(\text{Serf}(z) = z \cdot \text{erf}(\ln(1 + \exp(z)))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Serf() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SiELU[source]
Applies the SiELU activation function:
\(\text{SiELU}(z) = z \cdot \sigma\left(\sqrt{\frac{2}{\pi}} z + 0.044715 z^3\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SiELU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SinLU(a: float = 1.0, b: float = 1.0, inplace: bool = False)[source]
Applies the Sinu-sigmoidal Linear Unit activation function:
\(\text{SinLU}(x) = (x + a \cdot \sin (b \cdot x)) \sigma (x)\)
- Parameters:
a (float, optional) – Initial value for sine function magnitude. Default: 1.0.
b (float, optional) – Initial value for sine function period. Default: 1.0.
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Here is a plot of the function and its derivative:
Examples:
>>> m = nn.SinLU(a=5.0, b=6.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SinSig[source]
Applies the SinSig activation function:
\(\text{SinSig}(z) = z \cdot \sin\left(\frac{\pi}{2} \sigma(z)\right)\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SinSig() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Smish(a: float = 1.0, b: float = 1.0)[source]
Applies the Smish activation function:
\(\text{Smish}(z) = a \cdot z \cdot \tanh(\ln(1 + \sigma(b \cdot z)))\)
where \(\sigma\) is the sigmoid function.
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Sigmoid scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Smish(a=1.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.Suish[source]
Applies the Suish activation function:
\(\text{Suish}(z) = \max(z, z \cdot \exp(-|z|))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = Suish() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SwAT[source]
Applies the SwAT activation function:
\(\text{SwAT}(z) = z \cdot \frac{1}{1 + \exp(-\arctan(|z|))}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SwAT() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.SymmetricalGaussianErrorLinearUnit(a: float = 1.0)[source]
Applies the Symmetrical Gaussian Error Linear Unit activation function:
\(\text{SGELU}(z) = a \cdot z \cdot \text{erf}\left(\frac{z}{\sqrt{2}}\right)\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = SymmetricalGaussianErrorLinearUnit(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.TangentBipolarSigmoidReLU[source]
Applies the Tangent Bipolar Sigmoid ReLU activation function:
\(\text{TangentBipolarSigmoidReLU}(z) = z \cdot \tanh\left(\frac{1 - \exp(-z)}{1 + \exp(-z)}\right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentBipolarSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.TangentSigmoidReLU[source]
Applies the Tangent Sigmoid ReLU activation function:
\(\text{TangentSigmoidReLU}(z) = z \cdot \tanh(\sigma(z))\)
where \(\sigma\) is the sigmoid function.
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TangentSigmoidReLU() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.TanhExp[source]
Applies the TanhExp activation function:
\(\text{TanhExp}(z) = z \cdot \tanh(\exp(z))\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhExp() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.sigmoid_weighted.TripleStateSwish(a: float = 1.0, b: float = 2.0, inplace: bool = False)[source]
Applies the Triple State Swish activation function:
\(\text{TSS}(z) = z \cdot \frac{1}{1 + \exp(-z)} \left( \frac{1}{1 + \exp(-z)} + \frac{1}{1 + \exp(-z+a)} + \frac{1}{1 + \exp(-z+b)} \right)\)
- Parameters:
a (float, optional) – First shift parameter. Default: 1.0
b (float, optional) – Second shift parameter. Default: 2.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TripleStateSwish(a=1.5, b=2.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Max Sigmoid-based
- class torch_activation.classical.maxsig.DifferenceELU(a: float = 1.0, b: float = 1.0)[source]
Applies the Difference ELU activation function:
\(\text{DifferenceELU}(z) = \begin{cases} z, & z \geq 0 \\ a(z\exp(z) - b\exp(bz)), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = DifferenceELU(a=1.0, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.DualELU(alpha: float = 1.0, dim: int = -1)[source]
Applies the Dual ELU activation function:
\(\text{DualELU}(z, z') = \text{ELU}(z) - \text{ELU}(z')\)
- Parameters:
alpha (float, optional) – The alpha value for the ELU formulation. Default: 1.0
dim (int, optional) – The dimension on which to split the input. Default: -1
- Shape:
Input: \((*, N, *)\) where * means any number of dimensions
Output: \((*, N/2, *)\) where * means any number of dimensions
Examples:
>>> m = DualELU() >>> x = torch.randn(4, 2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.ElasticAdaptivelyParametricCompoundedUnit(a: float = 1.0, b: float = 1.0, num_parameters: int = 1)[source]
Applies the Elastic Adaptively Parametric Compounded Unit activation function:
\(\text{ElasticAdaptivelyParametricCompoundedUnit}(z_i) = \begin{cases} b_i z_i, & z_i \geq 0 \\ a_i z_i \cdot \tanh(\ln(1 + \exp(a_{i}z_{i}))), & z_i < 0 \end{cases}\)
- Parameters:
a (float or Tensor, optional) – Negative slope parameter. Default: 1.0
b (float or Tensor, optional) – Positive slope parameter. Default: 1.0
num_parameters (int, optional) – Number of parameters if using per-channel parameterization. Default: 1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ElasticAdaptivelyParametricCompoundedUnit(a=0.5, b=1.5) >>> x = torch.randn(2) >>> output = m(x) >>> # Per-channel parameterization >>> m = ElasticAdaptivelyParametricCompoundedUnit(num_parameters=3) >>> x = torch.randn(3, 5) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.ExponentialLinearSigmoidSquashing[source]
Applies the Exponential Linear Sigmoid Squashing activation function:
\(\text{ExponentialLinearSigmoidSquashing}(z) = \begin{cases} \frac{z}{1 + \exp(-z)}, & z \geq 0 \\ \frac{\exp(z) - 1}{1 + \exp(-z)}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.FasterPowerFunctionLinearUnit[source]
Applies the Faster Power Function Linear Unit activation function:
\(\text{FasterPowerFunctionLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ z + \frac{z^2}{\sqrt{1 + z^2}}, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = FasterPowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.HardExponentialLinearSigmoidSquashing[source]
Applies the Hard Exponential Linear Sigmoid Squashing activation function:
\(\text{HardExponentialLinearSigmoidSquashing}(z) = \begin{cases} z \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z \geq 0 \\ (1 + \exp(-z)) \cdot \max\left(0, \min\left(\frac{z+1}{2}, 1\right)\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardExponentialLinearSigmoidSquashing() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.HardSReLUE(a: float = 1.0)[source]
Applies the Hard SReLUE activation function:
\(\text{HardSReLUE}(z) = \begin{cases} az \cdot \max\left(0, \min\left(1, \frac{z+1}{2} + z\right)\right), & z \geq 0 \\ a(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = HardSReLUE(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.InversePolynomialLinearUnit(a: float = 1.0)[source]
Applies the Inverse Polynomial Linear Unit activation function:
\(\text{InversePolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 + |z|^a}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = InversePolynomialLinearUnit(a=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.LSReLU(a: float = 1.0, b: float = 1.0)[source]
Applies the LSReLU activation function:
\(\text{LSReLU}(z) = \begin{cases} \frac{z}{1 + |z|}, & z \leq 0 \\ z, & 0 \leq z \leq b \\ \log(az + 1) + |\log(ab + 1) - b|, & z \geq b \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > b. Default: 1.0
b (float, optional) – Threshold parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LSReLU(a=0.5, b=2.0) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.LeakyScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 0.1)[source]
Applies the Leaky Scaled Exponential Linear Unit activation function:
\(\text{LeakyScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1) + acz, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Leaky slope. Default: 0.1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = LeakyScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.LipschitzReLU(p_fn=None, n_fn=None)[source]
Applies the Lipschitz ReLU activation function:
\(\text{LipschitzReLU}(z) = p(z | z > 0) + n(z | z \leq 0)\)
where p and n are positive and negative functions with Lipschitz constant <= 1.
- Parameters:
p_fn (callable, optional) – Positive function. Default: identity
n_fn (callable, optional) – Negative function. Default: zero
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> # Default implementation (standard ReLU) >>> m = LipschitzReLU() >>> x = torch.randn(2) >>> output = m(x) >>> # Custom implementation with leaky behavior >>> m = LipschitzReLU(p_fn=lambda x: x, n_fn=lambda x: 0.1 * x) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.PolynomialLinearUnit[source]
Applies the Polynomial Linear Unit activation function:
\(\text{PolynomialLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{1}{1 - z} - 1, & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PolynomialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.PowerFunctionLinearUnit[source]
Applies the Power Function Linear Unit activation function:
\(\text{PowerFunctionLinearUnit}(z) = z \cdot \frac{1}{2} \left( 1 + \frac{z}{\sqrt{1 + z^2}} \right)\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerFunctionLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.PowerLinearUnit(a: float = 1.0)[source]
Applies the Power Linear Unit activation function:
\(\text{PowerLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ (1 - z)^{-a} - 1, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Power parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = PowerLinearUnit(a=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.RSigELU(a: float = 1.0)[source]
Applies the RSigELU activation function:
\(\text{RSigELU}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \geq z \geq 1 \\ a(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELU(a=1.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.RSigELUD(a: float = 1.0, b: float = 1.0)[source]
Applies the RSigELUD activation function:
\(\text{RSigELUD}(z) = \begin{cases} z \cdot \frac{1}{1 + \exp(-z)} a + z, & 1 < z < \infty \\ z, & 0 \leq z \leq 1 \\ b(\exp(z) - 1), & -\infty < z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter for z > 1. Default: 1.0
b (float, optional) – Scale parameter for z < 0. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = RSigELUD(a=1.5, b=0.8) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.ScaledExponentialLinearUnit(a: float = 1.67326, b: float = 1.0)[source]
Applies the Scaled Exponential Linear Unit activation function:
\(\text{ScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(z) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.67326
b (float, optional) – Alpha parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentialLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.ScaledExponentiallyRegularizedLinearUnit(a: float = 1.0, b: float = 1.0)[source]
Applies the Scaled Exponentially Regularized Linear Unit activation function:
\(\text{ScaledExponentiallyRegularizedLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ abz\exp(z), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Regularization parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledExponentiallyRegularizedLinearUnit(a=1.5, b=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.ScaledScaledExponentialLinearUnit(a: float = 1.0, b: float = 1.0, c: float = 1.0)[source]
Applies the Scaled Scaled Exponential Linear Unit activation function:
\(\text{ScaledScaledExponentialLinearUnit}(z) = \begin{cases} az, & z \geq 0 \\ ab(\exp(cz) - 1), & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Scale parameter. Default: 1.0
b (float, optional) – Alpha parameter. Default: 1.0
c (float, optional) – Exponential scale parameter. Default: 1.0
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = ScaledScaledExponentialLinearUnit(a=1.5, b=1.0, c=0.5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.maxsig.TanhLinearUnit[source]
Applies the Tanh Linear Unit activation function:
\(\text{TanhLinearUnit}(z) = \begin{cases} z, & z \geq 0 \\ \frac{2}{1 + \exp(-z)} - 1, & z < 0 \end{cases} = \begin{cases} z, & z \geq 0 \\ \tanh\left(\frac{z}{2}\right), & z < 0 \end{cases}\)
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = TanhLinearUnit() >>> x = torch.randn(2) >>> output = m(x)
- forward(x) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Chaotic Activation Functions
- class torch_activation.classical.caf.CCAF(a: float = 0.5, b: float = 0.5, iterations: int = 1)[source]
Applies the Cascade Chaotic Activation Function:
\[f(z_{i+1}) = a \cdot \sin(\pi \cdot b \cdot \sin(\pi z_i))\]where \(a, b \in [0, 1]\).
- Parameters:
a (float, optional) – Amplitude parameter. Default:
0.5b (float, optional) – Inner sine scaling parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.CCAF() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.CCAF(a=0.8, b=0.7, iterations=3) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.caf.FCAF_Hidden(r: float = 4.0, a: float = 0.0, b: float = 0.5, iterations: int = 1)[source]
Applies the Fusion of Chaotic Activation Function for hidden units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i)\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Hidden() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Hidden(r=3.9, a=0.1, b=0.3, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.caf.FCAF_Output(r: float = 4.0, a: float = 0.0, b: float = 0.5, c: float = 1.0, d: float = 0.0, iterations: int = 1)[source]
Applies the Fusion of Chaotic Activation Function for output units:
\[f(z_{i+1}) = rz_i(1 - z_i) + z_i + a - \frac{b}{2\pi} \sin(2\pi z_i) + \exp(-cz_i^2) + d\]- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0a (float, optional) – Linear shift parameter. Default:
0.0b (float, optional) – Sinusoidal amplitude parameter. Default:
0.5c (float, optional) – Gaussian width parameter. Default:
1.0d (float, optional) – Constant shift parameter. Default:
0.0iterations (int, optional) – Number of iterations for the chaotic map. Default:
1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.FCAF_Output() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.FCAF_Output(r=3.9, a=0.1, b=0.3, c=2.0, d=0.1, iterations=2) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.caf.HCAF(r: float = 4.0, iterations: int = 3)[source]
Applies the Hybrid Chaotic Activation Function:
\[ \begin{align}\begin{aligned}a_i = \sigma(z_i)\\c_{i,1} = ra_i(1 - a_i)\\c_{i,j} = rc_{i,j-1}(1 - c_{i,j-1})\end{aligned}\end{align} \]where \(\sigma(z_i)\) is the logistic sigmoid and \(r = 4\) by default.
- Parameters:
r (float, optional) – Chaotic parameter. Default:
4.0iterations (int, optional) – Number of iterations for the chaotic map. Default:
3
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = torch_activation.HCAF() >>> x = torch.randn(2) >>> output = m(x) >>> m = torch_activation.HCAF(r=3.9, iterations=5) >>> x = torch.randn(2) >>> output = m(x)
- forward(x: Tensor) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Gated Linear Units
Squared Linear Units
- class torch_activation.classical.squared.ISRLU(a: float = 1.0, inplace: bool = False)[source]
Applies the ISRLU (Inverse Square Root Linear Unit) activation function:
\(\text{ISRLU}(z) = \begin{cases} z, & z \geq 0 \\ \frac{z}{\sqrt{1 + az^2}}, & z < 0 \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRLU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.ISRU(a: float = 1.0, inplace: bool = False)[source]
Applies the ISRU (Inverse Square Root Unit) activation function:
\(\text{ISRU}(z) = \frac{z}{\sqrt{1 + az^2}}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.ISRU(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.ISRU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.LinQ(a: float = 1.0, inplace: bool = False)[source]
Applies the LinQ (Linear Quadratic) activation function:
\(\text{LinQ}(z) = \begin{cases} az + 1 - 2z + z^2, & z \geq 2 - 2a \\ \frac{1}{4}z(4 - |z|), & -2 + 2a < z < 2 - 2a \\ az - 1 - 2z + z^2, & z \leq -2 + 2a \end{cases}\)
- Parameters:
a (float, optional) – Shape parameter. Default: 1.0
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LinQ(a=0.5) >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LinQ(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.LogSQNL(inplace: bool = False)[source]
Applies the LogSQNL (Logarithmic Square Non-Linear) activation function:
\(\text{LogSQNL}(z) = \begin{cases} 1, & z > 2 \\ \frac{1}{2}z - \frac{z^2}{4} + \frac{1}{2}, & 0 \leq z \leq 2 \\ \frac{1}{2}z + \frac{z^2}{4} + \frac{1}{2}, & -2 \leq z < 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.LogSQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.LogSQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.MEF(inplace: bool = False)[source]
Applies the MEF (Modified Error Function) activation function:
\(\text{MEF}(z) = \frac{z}{\sqrt{1 + z^2} + 2}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.MEF() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.MEF(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SQLU(inplace: bool = False)[source]
Applies the SQLU (Square Linear Unit) activation function:
\(\text{SQLU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{4}, & -2 \leq z \leq 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SQMAX(c: float = 0.0, dim: int = -1)[source]
Applies the SQMAX (Square Maximum) activation function:
\(\text{SQMAX}(z_j) = \frac{(z_j + c)^2}{\sum_{k=1}^N (z_k + c)^2}\)
- Parameters:
c (float, optional) – Offset parameter. Default: 0.0
dim (int, optional) – A dimension along which SQMAX will be computed. Default: -1
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQMAX(c=1.0) >>> x = torch.randn(2, 3) >>> output = m(x) >>> m = nn.SQMAX(dim=0) >>> x = torch.randn(2, 3) >>> output = m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SQNL(inplace: bool = False)[source]
Applies the SQNL (Square Non-Linear) activation function:
\(\text{SQNL}(z) = \begin{cases} 1, & z > 2 \\ z - \frac{z^2}{4}, & 0 \leq z \leq 2 \\ z + \frac{z^2}{4}, & -2 \leq z < 0 \\ -1, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SQNL() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SQNL(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SqREU(inplace: bool = False)[source]
Applies the SqREU (Square Rectified Exponential Unit) activation function:
\(\text{SqREU}(z) = \begin{cases} z, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqREU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqREU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SqSoftplus(inplace: bool = False)[source]
Applies the SqSoftplus (Square Softplus) activation function:
\(\text{SqSoftplus}(z) = \begin{cases} z, & z > \frac{1}{2} \\ z + \frac{(z + \frac{1}{2})^2}{2}, & -\frac{1}{2} \leq z \leq \frac{1}{2} \\ 0, & z < -\frac{1}{2} \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SqSoftplus() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SqSoftplus(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.SquaredReLU(inplace: bool = False)[source]
Applies the SquaredReLU activation function:
\(\text{SquaredReLU}(z) = \begin{cases} z^2, & z > 0 \\ 0, & z \leq 0 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.SquaredReLU() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.SquaredReLU(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class torch_activation.classical.squared.Squish(inplace: bool = False)[source]
Applies the Squish activation function:
\(\text{Squish}(z) = \begin{cases} z + \frac{z^2}{32}, & z > 0 \\ z + \frac{z^2}{2}, & -2 \leq z \leq 0 \\ 0, & z < -2 \end{cases}\)
- Parameters:
inplace (bool, optional) – can optionally do the operation in-place. Default:
False
- Shape:
Input: \((*)\), where \(*\) means any number of dimensions.
Output: \((*)\), same shape as the input.
Examples:
>>> m = nn.Squish() >>> x = torch.randn(2) >>> output = m(x) >>> m = nn.Squish(inplace=True) >>> x = torch.randn(2) >>> m(x)
- forward(z) Tensor[source]
Define the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Utilities
- torch_activation.utils.plot_activation(activation: Module, params: dict = {}, save_dir='./images/activation_images', x_range=(-5, 5), y_range=None, preview=False, plot_derivative=True)[source]
Plot the activation function and optionally its derivative.
- Parameters:
activation (torch.nn.Module) – The activation function to plot.
params (dict) – A dictionary of parameter names and values for the activation function.
save_dir (str, optional) – The directory to save the generated image. Defaults to “./images/activation_images”.
x_range (tuple, optional) – The x-axis range for the plot. Defaults to (-5, 5).
y_range (tuple, optional) – The y-axis range for the plot. Defaults to None (auto-scale).
preview (bool, optional) – Whether to display the plot interactively. Defaults to False.
plot_derivative (bool, optional) – Whether to plot the derivative of the activation function. Defaults to True.
- Returns:
None
The function plots the activation function and, optionally, its derivative for the given parameters. The resulting plot is saved as an image in the specified save_dir directory.
If preview is set to True, the plot will also be displayed interactively.
Example:
>>> # Plotting the sigmoid activation function and its derivative >>> params = {'n': 1.0} >>> plot_activation(torch.nn.Sigmoid(), params)